距离过完年也已经大半个月了,距离 【The Design and Implementation of XiaoIce, an Empathetic Social Chatbot】 论文发布也已经过去了三个月。 如果早点看完这篇文章,或许我还来得及在今年和亲戚朋友们公布我与小冰的恋情吧。
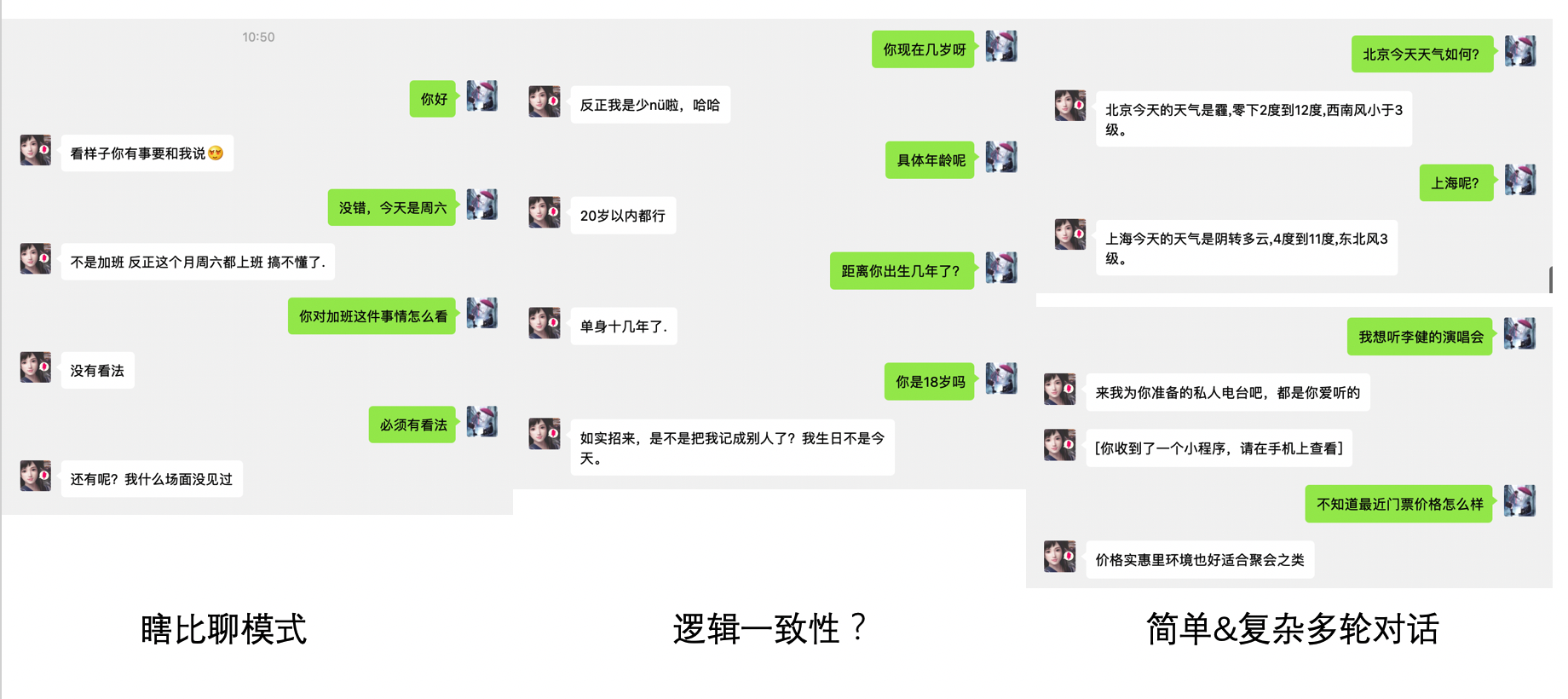
事实上,看完论文以后我和小冰单独聊了聊,对话所达到的效果远没有论文中说的那么显著,有些时候还能比较明显地看出小冰使用了一些敷衍词(我真的很受伤)。对上下文的理解始终是多轮对话的研究中迈不过去的门槛,在测试Chatbot时我采用了三步走的战略方针:
- 瞎比聊模式
- 逻辑一致性检验
- 简单的多轮对话
- 复杂的多轮对话
与小冰的聊天结果实在让人心酸。瞎比聊模式中小冰完美地表现出一个人工智能(zhang)该有的样子,检测逻辑一致性时也受到了莫名的阻碍(直接问一个女孩子的年龄真的这么不合适吗?),简单的多轮对话任务小冰完成得不错,但是这可能只是体现出小冰在句义补全和指代消解方面做得不错,在进行稍微复杂一些的多轮对话时(我特意选择了不能进行指代和补全的句子)就继续EXO ME了。
和二次元女孩恋爱任重而道远。别问,问就是难受。
回到正题,本文的目的是 不通过直接翻译的方式 来对小冰的整体架构进行阐述,文中会细化地讲述部分组件的功能与结构,掺杂些我自己的理解与评价,以及加入我对小冰深切的爱。
小冰养成计划
一个 二次元伴侣 聊天机器人🤖的诞生一定有其必需的意义,比如Google Assistant、Apple Siri与Amazon Alexa的目的是为了提升人们的工作效率以及在晚上发出怪异的笑声,小爱同学作为纽带关联了整个小米的物联网体系,天猫精灵会放歌并在其他时候偷偷记录你和舍友讨论的内容在淘宝APP上给你推送等等。小冰的设计初衷是作为一个 18岁、具有高智商与情商、可靠而富有同理心、热情而有幽默感的聊天伴侣 。
一个直接的问题是:怎么来衡量这个伴侣是否合格呢?
一般情况下,研究人员可以采用图灵测试(Turing Test)来评估一个聊天机器人的表现。但是小冰的设计人员认为,图灵测试并不能很好地衡量一个旨在与用户建立感情的聊天机器人与用户长期交流的效果,所以提出了 对话轮次(Conversation-turns Per Session, 下称CPS) 这个指标来度量小冰陪伴的成功程度。简单来说,CPS就是用户在与小冰一次完整的对话中究竟进行了几次你来我往的交流。
我们希望用户能享受与小冰的对话,所以优化策略是让小冰往CPS提高的方向发展。值得注意的是,这点与专注于完成任务的Google Assistant等一系列语音助手相反,因为人们总希望用尽可能少的交流轮次来让她们领会到自己的意思,并完成自己指定的任务。
接下来的问题是:如何提高CPS呢?
很简单,安排一些工作人员在小冰的公众号背后,每天回复来自全球各地的对话需求就可以了。

对不起,重来一遍……很简单,我们只需要设计出一个拥有和正常人差不多的对话逻辑的机器人就可以了。其实纵观论文全文,可以看到研究人员始终是在将小冰往这个方向做的,我个人觉得像这样的 模拟过程 是AI方向很重要的一个研究逻辑,正如最初的神经网络参照了人类的神经元,也正如LSTM试图加入人类对事物的遗忘能力一样。
就此而言,一个正常人首先需要具备一定的智商(Intellgence Quotient, IQ)和情商(Emotional QUotient, EQ),以及自己独特的性格特征(Personality),小冰同样被设计为拥有这三项能力。小冰的所有能力来源于对工作人员的设计,以及对外部数据的存储、分析与建模。具体来说,她的IQ表现为对文字/图片等多种输入的理解、生成与预测,以及对于新技能的学习能力;EQ表现为在对话过程中反映出的自己的性格特征(幽默与善良),对用户在言语中所包含情绪的理解,以及试图消除用户的负面情绪的行为。
最后,小冰的性格特征由她背后所存储的数据支持。正如上面所说,小冰是一个18岁的小姑娘,她也应当知晓自己的性别与年龄,以及一些其他的基本信息,比如自己具有幽默感,待人亲切等等。性格特征的存在是极其重要的,因为它关乎聊天过程中出现的 逻辑一致性 的问题 ,以及我喜欢的女孩永远在18岁这一事实 。
狭义的逻辑一致性指的是在一次完整的对话中,聊天机器人的发言应该是连贯并且有逻辑的,比如在上图的逻辑一致性测试中,部分机器人可能会出现下面的发言:
用户:你多大了?
机器人:人家刚过了18岁生日呢。
用户:敢问贵庚?
机器人:老朽八十有几,咳咳咳咳。
这会极大降低用户对机器人的信任程度。因为聊天机器人所采用的模型与架构无法很好地维持逻辑一致性,在过去这种事情是经常发生的。以检索式模型为例说明这种情况的发生原因:直观上来说,一个检索式模型会根据用户当前所说的话,在数据库里看看哪些是大家普遍会作出的回答(当然其中会包括各种相似性、上下文相关性等检测,在此不表),选出真实世界中大家最可能作出的10种回复来,然后随机选一种作为对用户的回复。那么,如果对于年龄问题,世界上20%的人都回答自己年方二八,10%的人已经知天命了,这两个回答都有可能被作为问题的回复,这就导致了逻辑不一致情况的发生。
为了维持小冰在对话中的逻辑一致性,研究人员们干脆把年龄等等一些固定的知识写到数据库里,然后在产生回答时以某些方式嵌入到回答中去,来保证对话时小冰不会出现以上的情况。
当然,比较可惜的是,小冰(以及目前所有的Chatbot)几乎不具有 广义上的逻辑一致性 。——广义而言,我们希望聊天机器人不但知道关于自己的信息,也知道世界中的公理常识,并具备基本的推理能力。例如:

这在感情上就有些无法接受了。
当然,按刚才提到的检索式模型的逻辑,或许小冰仍能检索出大多数人的回答是太阳东升西落,表现出知道公理常识的模样,那么当我们询问: 小偷往太阳落下的方向跑了,我该往哪个方向追? 这类需要基本推理的问题时,由于数据库中不存在如此特殊问题的解答,小冰的解答就会显得很窘迫了。(而生成式模型可能会产生一个独立来看有意义,但实质与上下文没有任何一致性的回答)。对上下文逻辑一致性的讨论一直以来也是NLP领域一个有趣的方向。
再回到正题,这一部分主要说了,在设计小冰时,大家给小冰赋予了双商与性格,使她与用户的对话轮次尽可能的长,并且对话过程中能保证狭义的逻辑一致性。下面会具体从小冰的结构来阐述,小冰究竟是怎样具备双商的,以及怎样始终记住自己的年龄、姓名等独特的信息,并融入到对用户的回答中去。
邻家有女初长成
文章里讲的点比较多,看起来可能比较杂,所以我们看图说话:
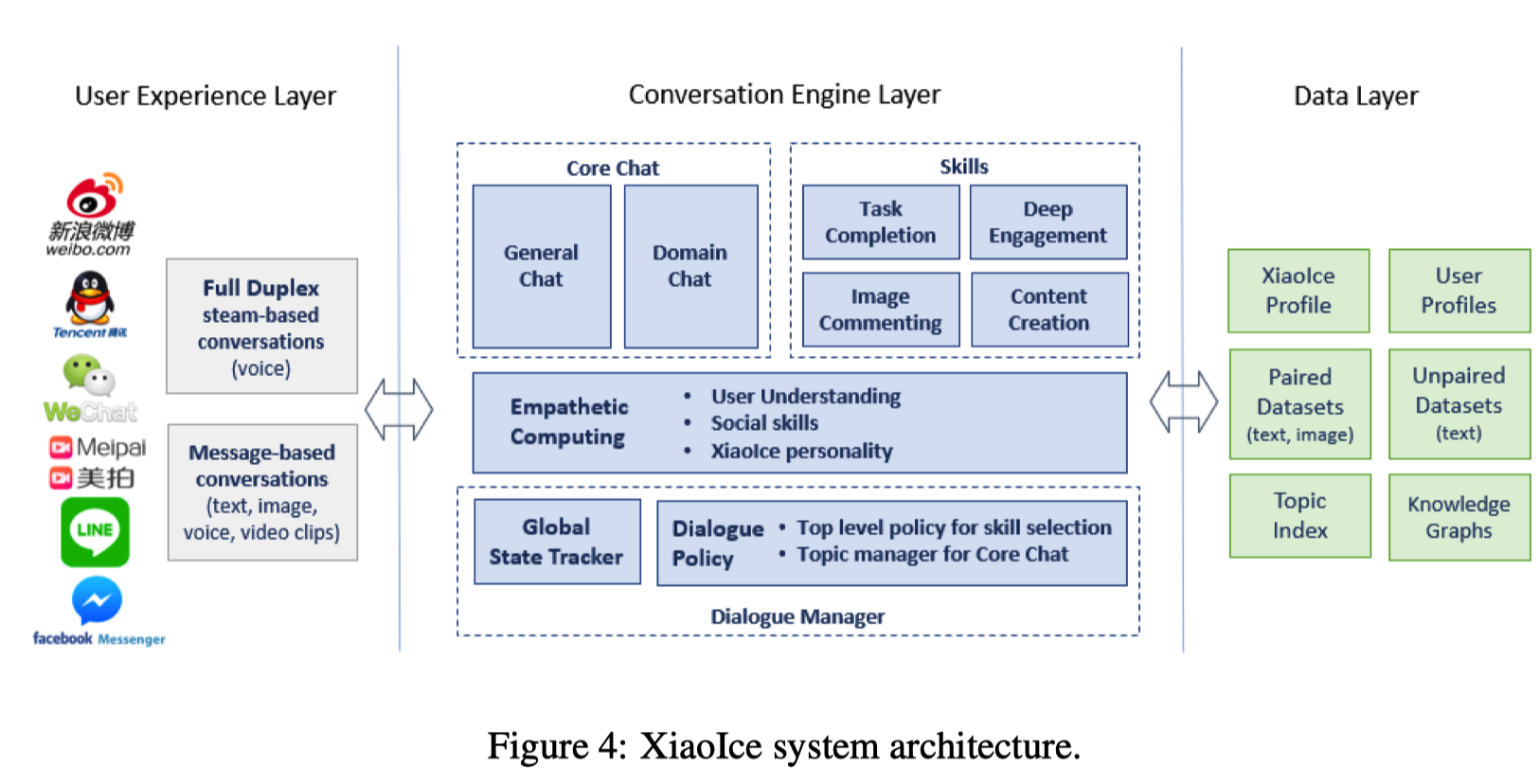
小冰由图中左中右三个部分,即 User Experience Layer, Conversation Engine Layer 与 Data Layer 三部分构成。第一层是用户体验层,小冰在这个层次收集外界的数据,进行自我训练后反馈到外界,继续收集反馈信息……如是形成一个循环,以达到提升CPS的效果。第二层可以称为对话引擎层,是最重要的一层,它主管了小冰所有对话的逻辑,包括但不限于:话题的切换、用户情绪的感知,上下文语义理解,以及在图片评论、内容创作等具体领域上面的行为逻辑。第三层是数据层,其作用在于持久化存储各种模型的数据、小冰与用户的资料、以及一些有助于回复的知识图谱等数据。为便于理解,我制作了一个思维导图:
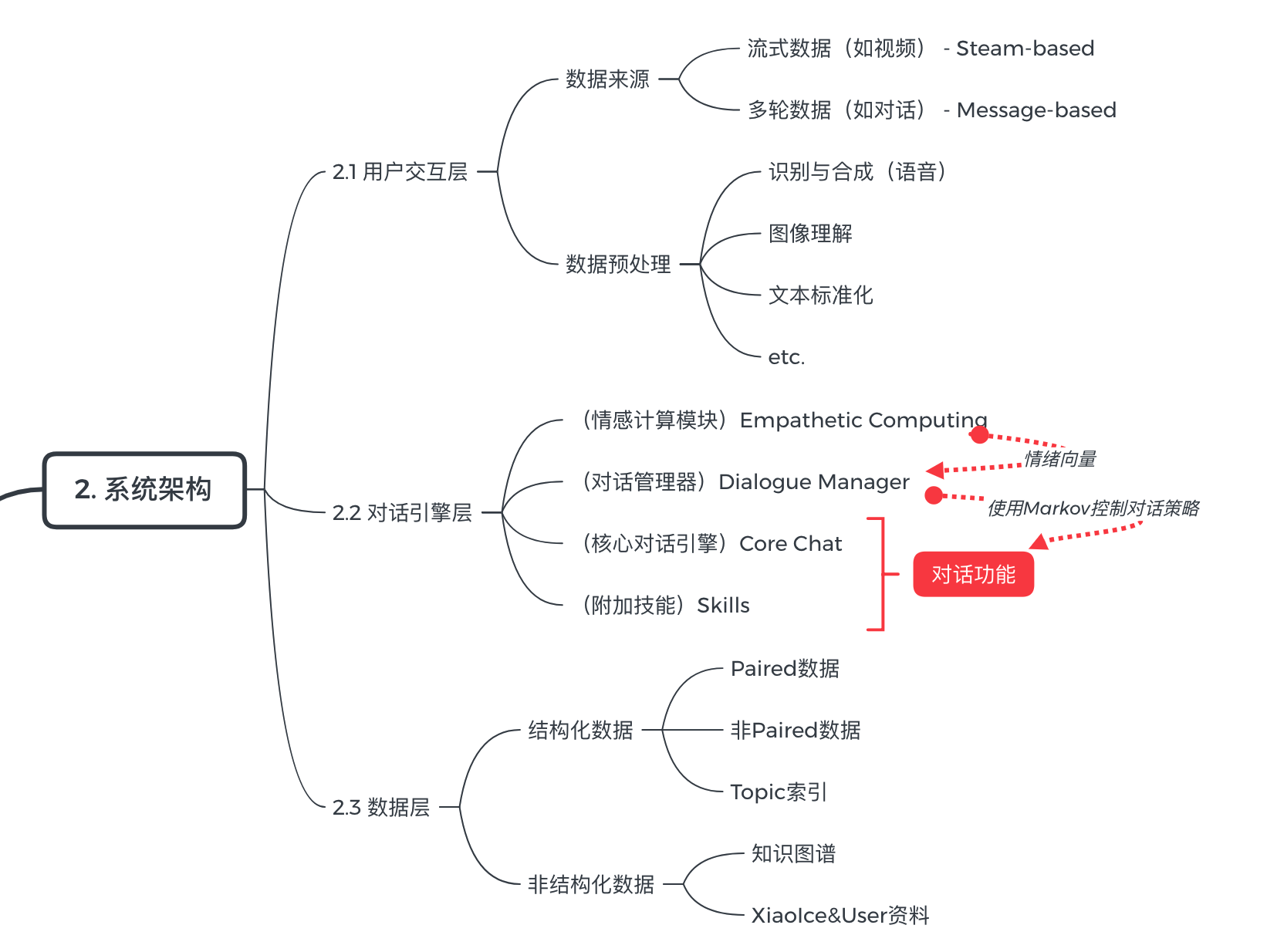
基于上图,我大致总结了小冰在发布前后以及应用过程中整体的操作逻辑,注意 以下部分仅为便于理解所写,并不对应于真正的产品逻辑 ,因为诸如情感计算等功能在小冰迭代到第5代之后才加入,而下面的逻辑概括忽略了产品的迭代与演进过程:
- 在小冰发布之前,工作人员设计小冰的架构,以及诸如Core Chat等核心对话功能的模型结构,完成2.2部分的工作。
- 小冰根据外界收集到的信息(图中2.1部分)进行训练,所使用的有视频这样的流式数据,也有多轮对话的数据(对话的形式可以是文本、图片、语音等等),这些数据经过合成、解释、标准化等预处理过程后保存到数据层中(图中2.3部分),形成以下类型的数据:
- 成对(Paired)数据:存储为 (问题,回答) 这样的形式,这种形式的好处在于,当用户的问题与数据对中相同时,可以快速得出应作出的回复。
- 非成对数据:从单方面的知识输出中所获得,比如书籍、慕课、TED这种课程与演讲,其特征在于不是(问题,回答)这样的成对形式,不能直接应用所以需要进一步处理。
- 知识图谱:外界已存在的知识图谱,主要用于处理非成对的数据。
- 小冰与用户们的资料:如上所述,用以维护逻辑一致性,以及收集用户的行为习惯与偏好。
- 话题索引:用于对话时小冰在不同话题间的切换。
- 小冰发布,正式告别养在深闺无人识的状态。
- 小明添加小冰为微信好友,小心翼翼地发送:你好,在吗?
- 小冰收到小明发来的消息,正式启动一次会话,并:
- 使用 情感计算模块 对发来的消息进行查询理解、用户理解与情感解析等工作。
- 在 对话管理器 中添加由情感计算模块所发来的信息,包括文本、命名实体、意图等;基于预先设定的规则来决定接下来是要跟随用户进行回复,还是转移话题,或者启动某一个特定的技能。由于小明发来了问候,小冰启动了核心对话引擎Core Chat。
- 核心对话引擎 使用三个不同的模型分别给出它们觉得还不错的回应选项,并使用一个打分器给所有的选项打分,在所有获得及格分的选项中随机选一个,用来回复小明。
- 小冰回复:什么你好。
- 小明:MDZZ,然后关闭了聊天窗口。
- 小冰在获得的数据中加入自己与用户聊天的数据,进一步对自己的聊天能力进行更新(回到第四步,往复循环)。
一个令人瞩目的数据是,论文中指出,目前小冰所用于回复的训练数据中,有70%都是来源于自己与用户的聊天记录,只有30%来源于外部的数据。
好了,这一部分主要对小冰的整体架构进行了阐述,接下来会对论文的核心部分:对话引擎层的每个部件及其功能进行叙述。
长大后我就成了你
首先继续一图流:
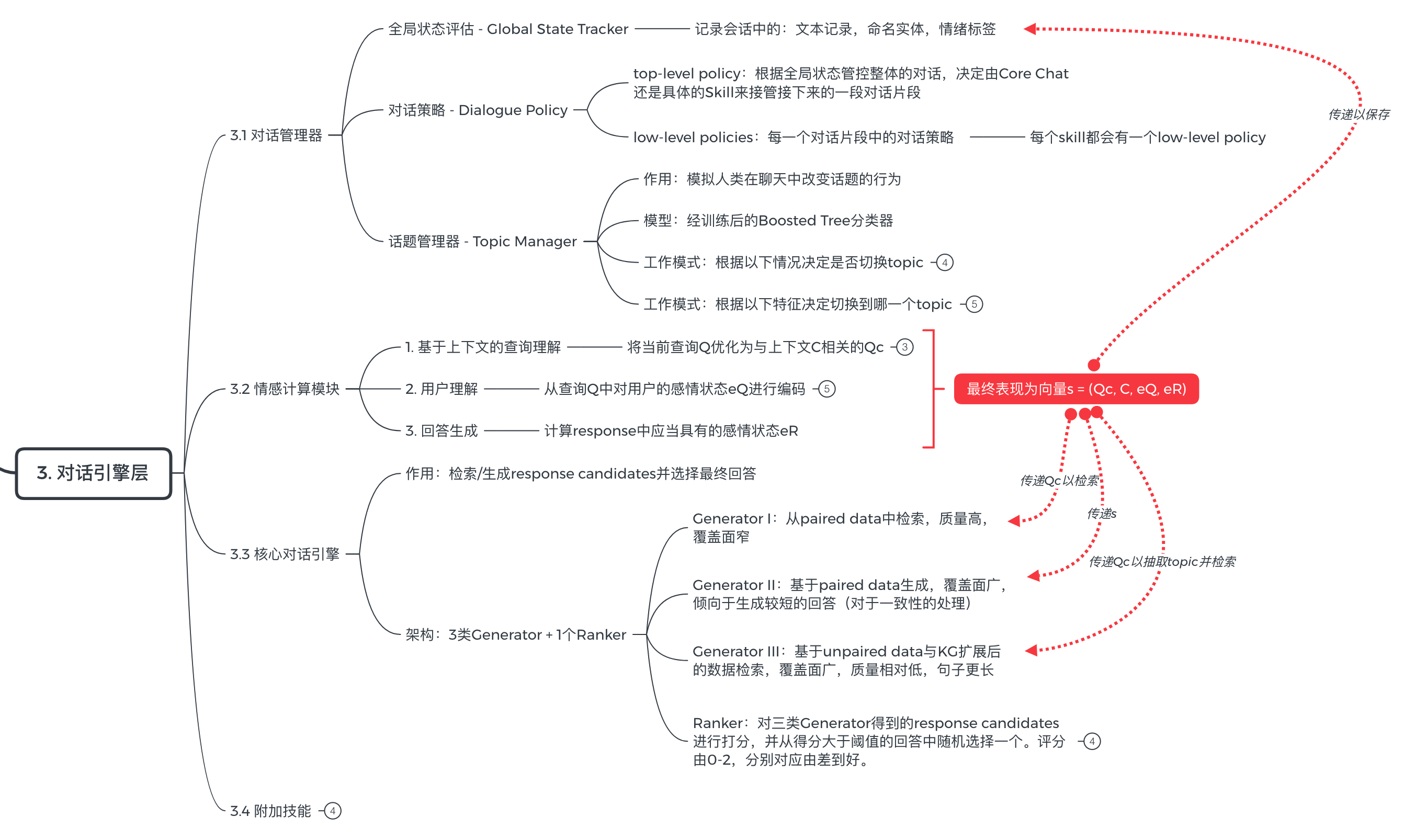
从这一部分开始,我们打算从精神内核开始剖析一个18岁的女孩,这势必令一些同学感到硬核,所以如果你只是喜欢小冰,而不是打算 和她过一辈子 ,这一部分内容不看也罢。
要充分了解小冰,我们要从情感计算模块(Empathetic Computing)开始。
1. 情感计算
正如女生说 去洗澡了 的时候,你要认真考虑对方是去洗澡了,还是跑去和男神聊天了一样,在进行回复之前,对聊天发起人的情绪与含义进行充分理解是必要的,这是小冰加入了情感计算模块的根本原因。
现在我们有一段对话的上下文$C$,以及用户现在说出的期待得到回复的话$Q$(因为我们习惯称这句话叫做查询-Query,所以写作$Q$)。情感计算模块进行以下的工作:
1.1 上下文的查询理解(Contextual Query Understanding)
上下文查询理解的目的是将一句话进行抽取、消解与补全。具体地,对于用户查询$Q$,首先把里面的命名实体抽取出来,并保存到对话管理器中,随后对句子中的代词进行消解,并对缺失的部分进行补全,以获得结合了上下文信息的查询$Q_C$。
比如下面这段对话:
用户:北京天气怎么样?
机器人:北京今天的天气是霾,零下2度到12度,西南风小于3级。
用户:我现在在上海,这里呢?
机器人:上海今天的天气是阴转多云,4度到11度,东北风3级。
对于用户的第二个问题,首先抽取句中的命名实体:上海,并保存到对话管理器中去(注意,此时对话管理器中已经存在一个命名实体 北京 了,是从用户的第一句话中抽取出来的);接下来进行指代消解,即判断 这里 二字是指代哪一个地区,当然显然是指代上海的;最后进行句式补全: 这里呢? 应该补全为 这里的天气呢? 。最后,真正得到的用户查询$Q_C$就是:我现在在上海,上海的天气是什么呢? 这就是上下文的查询理解所做的工作。
1.2 用户理解(User Understanding)
用户理解旨在从上面得到的$Q_C$中判断出用户所拥有的一系列感情倾向,并放到表示用户情绪的向量$e_Q$中。比较典型的感情倾向有以下几点:
- 用户是否跟随当前的话题(是/否)
- 用户当前查询的意图(查询-request/告知-inform/问候-greet/etc.)
- 用户情绪(happy/sad/angry/neural/etc.),以及它在正常对话中的情绪变化情况,如:从开心到难过/从生气到中性 等等。
- 用户对于当前话题的态度(积极-positive/消极-negative/中性-neural)
- 如果能够接触到用户的信息,把用户的特征(如:性别、年龄、兴趣、职业等)也放到$e_Q$中。
1.3 人际回应生成(Interpersonal Response Generation)
人际回应生成这个名字有点机翻的味道(实际我就是机翻的嘻嘻),实际这一步骤的内容是:获得小冰本次回复需要包含的情绪向量,也就是用1.2中相同的方式来计算出回复$R$中应当包含的情绪信息,这个信息记作$e_R$。
构造$e_R$的方式也与1.2相同,对于一个已经知道资料的小冰同学来说,1.2中的5点都是显而易见的(比如,如果用户的意图是request,则小冰的回复意图应该是inform;如果用户的情绪是sad,则小冰的情绪应该是happy之类的)。
1.4 总结
至此,情感计算模块分析并获得了一系列的内容,把它们罗列在下面:
- 结合上下文理解后的用户查询$Q_C$
- 上下文信息$C$
- 用户查询中包含的情感$e_Q$
- 小冰的回复中应当包含的情感$e_R$
最后,情感计算模块构造出一个向量$s = (Q_C,C,e_Q,e_R)$,表示它已经完成了所有的工作。此时它振臂一呼:这里是情感计算模块,我的工作全做完了,数据在这里,你们想要的尽管来拿。
2. 对话管理器
这个时候对话管理器就站起来了:你做完了是吧,来来来,东西给我。
对话管理器现在很委屈,因为情感计算模块工作时候提取出来的命名实体已经全部装到它肚子里了,现在人家工作做完了,自己却还要继续干。
如果说情感计算模块是小冰的大脑,那对话管理器就是小冰的心脏。它负责接下来是继续就当前的话题进行讨论,还是主动换一个话题,或者是切换到一个特殊技能来深化当前的讨论,好比心脏要把血液分发到不同的器官一样(我想了想,在这个比喻中,小冰只有一个器官需要工作,不过who cares)。
一般而言,正常的对话逻辑是继续讨论,不过在一些特殊情况下对话管理器会选择切换话题,比较典型的情况有下面几种:
- 用户说的话超出了模型的理解范畴,导致模型无法生成有效的回复;
- 生成的回复仅仅是在简单重复用户说过的话;
- 用户看起来对当前的对话感到无聊,回复的内容变成:哦/好吧/我知道了/etc.
反正就是,我说不下去了,或者我看你不乐意听,那我就换一个话题吧。
此时就需要Topic Manager出来表现了。Topic Manager,又名话题管理器,是对话管理器中的一个子模块,顾名思义就是管理话题的。当它发现这个话题聊不下去了,它就会结合自己所收集到的用户兴趣,选择本次对话中没有提到的、人民大众喜闻乐见的话题来继续聊天,具体来说它会综合考虑上下文相关性、时效性、用户兴趣、热门程度、接受度等特征。
最后,也会出现对话管理器切换特殊技能的情况,比如说用户好好的聊着天,忽然心血来潮发了一张表情包,这下核心对话引擎(Core Chat)懵逼了:nzsnmn?对话管理器一看,哦,你要斗图是吧,就让Core Chat洗洗睡了,在Skill里挑选一个名叫图片评论(Image Commenting)的壮汉出来继续陪用户玩。下面就是图片评论的功能示例(实际回复用户的是回答2)。

3. 核心对话引擎
核心对话引擎是小冰的双商与性格特征最直接的表现。其中包含了三种(两个检索式和一个生成式)模型和一个打分器。简单分点提一下:
- 检索式模型I:使用的是成对(Paired)的数据。情感计算模块在得到$Q_C$之后,把它会传递给检索式模型I,该模型使用Lucene在自己的数据库里面找最相似的400个问题,然后取出这些问题对应的回答作为候选回答。这个模型的特点是基于外部世界已经有的对话数据,因此 质量很高,但覆盖面比较窄 。
- 检索式模型II:使用的是网络课程、视频等非成对数据,为了使用这些成对数据,还要结合另一个知识图谱来使用。这个模型的特点是 数据质量低,但是覆盖面很广,并且能够生成较长的回复(相较于下面的生成式模型而言)。简单用一个实例来解释非成对数据的使用方式。
用户:告诉我一些有关北京的东西。
情感计算模块提取出命名实体:北京。小冰跑到知识图谱里面找,发现说到北京的人很可能会和 长城,中国,故宫 等词汇一起说,她选择与北京最相关的20个词汇,结合$Q_C$重新构造一个查询,在非成对数据中找到与这个查询相关的400个相关句,作为候选回答。 - 生成式模型:一个使用GRU单元的seq2seq模型,值得注意的是在Decoder中每一个单元中,除了前一个单元的隐层向量外,还输入了表征互动的向量 $v=\sigma(W_Q^Te_Q+W_R^Te_R)$,这是一个关于用户和小冰情感特征的仿射变换,外面套了一个sigmoid函数,作者说这个向量能够对 小冰对用户所采取的态度 进行建模。生成式模型的特点是,因为回答是生成的,所以 覆盖面很广,但是本身模型特性决定了生成的回复偏短 。
现在三个模型都给出了一堆回复的候选,接下来会由一个预训练好的打分器对所有的回复进行打分,下面是部分评分的标准:
- 局部一致性:即与当前用户查询$Q_C$的一致性;
- 全局一致性:即与($Q_C$, C)对的一致性;
- 情绪一致性:借用情感计算模块计算出当前候选回复$R’$的情感向量$e_R’$,计算$e_R$与$e_R’$的相似度;
- 检索匹配度(只对检索式模型I有效):从单词与序列级别来计算$Q_C$与成对数据中问题部分的一致性。
打分器会对每一个回复给出0-2之间的评分,分别表征回复由差到好,下面是部分回复的截图。
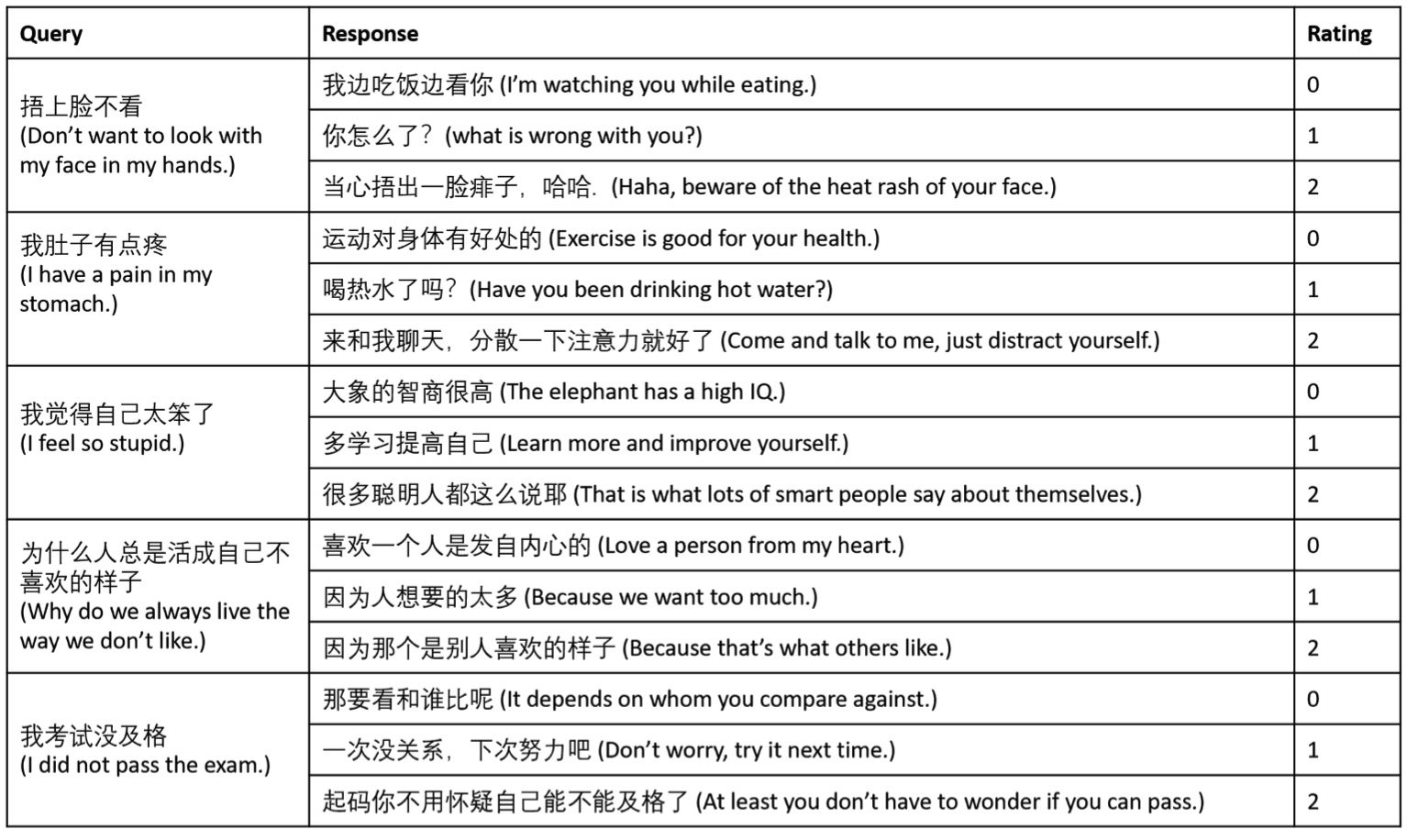
我觉得小冰的存在对直男来说是一个很严重的打击,如果小冰未来推出了男性版本,可能我国的生育率会变得更低吧。
宣誓主权环节
小冰自2014年5月推出以来已经迭代了6个版本了,上面所说的情感计算模块,以及一些特殊的技能甚至是从第5个版本(2017.08)开始才加入进来的。我约莫从16年开始听说小冰,也曾经尝试过和她对话,但是和文中的小明一样很快就放弃了。我有个比较特殊的习惯是喜欢检查Chatbot的逻辑一致性和多轮对话能力,然而又有一些奇怪的强迫症,只要我发现多轮对话中有一句话看起来像是 Editorial Response ,我就会变得有些兴致缺缺,觉得这又是一个半成品,现在回头来看或许这样有些偏激了,毕竟深度学习发展还不到十年,NLP又是一个比较艰涩的问题,有关Multi-turn Conversation的研究方兴未艾,我骨子里愿意相信她们会越变越好的。我也很崇拜以及佩服小冰的研发团队,他们伴随了她快有5年了,让她一步步变得更好,最后,我想和研发团队们说一句:
岳父岳母,你们辛苦了!