Sequential Matching Network: A New Architecture for Multi-turn Response Selection in Retrieval-Based Chatbots
乱七八糟的序
BDP课上组长大人布置下来的任务,是要研读这篇论文(因为名字太长了我写在了一级标题里面,让所有人都能第一时间看到它,下面统一使用SMN来指代论文中提出的模型)。我是属于 牵着不走,打着倒退 没人给出明确的任务目标就很难有动力主动学习的那种人,可能是高中时期延续下来的陋习,所以如果要给这篇post一个一级作者,那应该写 社会我强哥 才是。
回到正题,首先来简单说一下多轮对话现在的研究态势吧。
目前常用的对话建模方式有检索式、生成式以及两者融合的方式。
顾名思义,检索式就是对于一个提出的问题,我从当前已经有的资料中搜索出这个问题可能匹配的答案,候选答案可能有多个,但是在对话中最终回复的答案只能是一个,所以需要找到一种最优的算法来对这些候选答案进行筛选,选出可能性最大的那一个。
生成式模型是指我先把目前所有已知的知识用来训练出一个模型,然后不管你说什么,我都用这个模型来解读你的问题,并用模型的输出来回答。
最后,检索与生成相结合的方法就是把前两者糅合起来,正也因此可以玩得花里胡哨,比如用检索模型获得的候选答案们,我训练一个生成模型来对这些答案排个序,或者用生成模型生成的答案放在检索模型给出的候选答案中,一起参与 谁是大明星 的角逐,又或者对于一个检索式模型获得的答案,我用生成式模型对它进行改进,等等等等。
那么好了,下面要讲的SMN属于哪一种模型呢?当然是 两者结合的模型 检索式模型啦!
……
说实话,从资料里找来的定义,结合SMN的建模过程,我其实并不很明白为什么将它分在纯检索式模型里面,可能是上面的三种建模方式本身就没有一个很明确的分类界限,也可能是我的报道产生了偏差。我认为SMN中的$\mathrm{response}+\mathrm{reranking}$的工作模式更像第三类方法,如果我的理解有问题,务必请大家来花式打脸。
下面正式来叙述SMN的提出背景、相关研究,SMN的工作方式以及一些改进策略。
Background与related work
SMN提出在2017年的5月,那个时候关于multi-turn conversation的讨论方兴未艾。(私以为multi-turn chatbot之于single-turn是个从量到质的跨变,它意味着我舍友与它的天猫精灵谈恋爱的时候,后者会从之前的聊天记录中反复确认舍友对它的爱慕之情,而不是前脚刚说完’我也爱你’,后脚就开始回答’我不明白你在说什么’了)
多轮对话任务所面临的的challenge主要有以下两个方面:
- 如何来identify上下文中各种粒度的重要信息(如word/phrase/sentence级别的粒度)——准确识别这些信息能够更好地帮助我们选择合适的responses
- 如何对上下文中的utterances之间的关系进行建模——比如在一些特殊的时候,将某两个提问进行顺序的颠倒,会极大的改变整个对话的含义,因此保留utterances之间的relation或者顺序相关的信息是很有必要的。
那么我们知道,multi-turn与single-turn的根本区别就在于前者使用了前面$n$轮对话的先验知识,而如何使用这些知识来加强对于当前的conversation的理解,以对现在要回答的utterance做出更好的回复,就是研究的关键了。是时江湖上也已经对multi-turn conversation中先验知识的使用进行了研究,不过基本还是停留在 把前几轮的utterances简单concatenate起来(我的理解是进行向量层面的拼接) 或者 对于整个上下文进行一次抽象,然后对最终抽象出来的向量进行match 的程度。其实严格来说,neither前者还是后者都没有解决上文所说的两个challenge 说句题外话,我有时候会阴谋论的思考,论文是不是故意在所有challenge中唯独挑了当前算法没有解决的几个来说(因为SMN正好解决了上面的两个challenge)。如果真的是这样,那这个春秋笔法的使用实在是太值得我们学习了 。下面是对论文中关于related work的评价的摘录:
- 使用数据驱动的方法来构建一个chatbot从2011年起就开始引起了广泛的关注,主要包括了基于检索的方法与基于生成的方法(这个上面有提到)。
- 早期的基于检索的chatbot主要聚焦于single-turn conversation的回答检索,现在逐渐将目光转向了multi-turn conversation(这个上面有提到)。
- Lowe et al. (2015)提出将整个上下文的utterances进行拼接,来进行回复的匹配。
- Yan et al. (2016)拼接了上下文的utterances以及当前要回复的input message,使用这些信息来对query进行重构,然后放到深度神经网络结构中进行response的匹配。
- Zhou et al. (2016)使用multi-view的模型来进行多轮对话的reponse检索,其中包括了word view与utterance view。 这是一篇多轮对话领域很重要的文献,SMN中对数据的multi-level使用也一定程度上吸取了这篇文章的思想
好了,那么最后我们的SMN呢,是对每个utterance都进行了匹配,得到了每个utterance-response的表示对,然后它对根据这些对分别提取word与segment级别的信息,这样就把信息在multi-level中进行了表示,随后把这些向量按本身的顺序放到一个GRU的隐层里面进行encode。正如我们上面所说,这样的方法既保留了utterances之间提出的时间顺序,也保证了数据的多粒度使用。
模型简述
借论文中的图来简单说明一下SMN的模型结构:
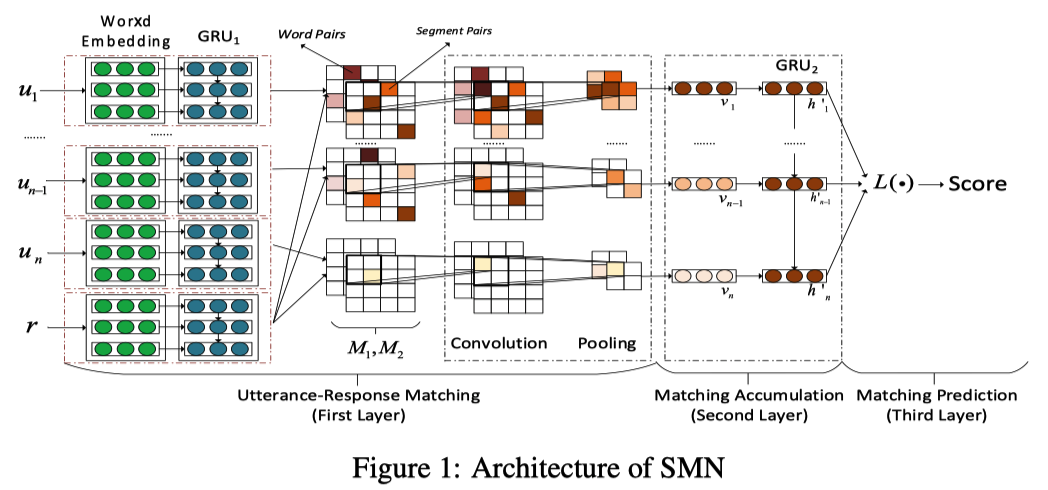
SMN的结构主要由三个部分构成(可以结合上图进行比对):
Utterance-Response Matching
第一部分是utterance-response matching部分:这个部分又由三个步骤构成,会在下面讲到。首先厘清这里面的输入与输出:这个模型最初的输入是一堆utterances和一个候选的response。其中utterance就是每一句对话(无论是谁说的),用下图简单说明:

这段对话里面包含了human与chabot对话记录,其中无论是人说的还是机器说的,我们不分贵贱都算作一个utterance。
在第一步中,主要目的是将文字转换成向量表示,我们查阅一个embedding table,把每个utterance与最后的那个response都转化成等长向量的形式。论文中对这部分的描述很少,只说了’the model looks up an embedding table and represents u and r as U and R’这样的,我比较奇怪这个embedding table是怎么构造出来的,文中也没有进行解释,复现的时候莫不是要用random walk+skip gram?——Anyway,假设我们成功获得了这些vectors,下一步我们把它放到GRU的隐层里面去做encoding,这样每个utterance都会被整个上下文信息所影响,最后的实际上已经是短语级别的vector了。
现在到了第二步,目的是计算两个level的相似度矩阵。在第一步中,我们已经获得了每个utterance的矩阵表示,假设某个utterance中有$n_u$个words,每个word都已经被编码成了长度为$d$的向量,那么这个utterance的最终数据规模就是$\mathbb{R}^{d\times n_u}$,同理,我们选择的response表示也为$\mathbb{R}^{d\times n_r}$,我们可以计算出utterance与response之间以word为单位的相似度矩阵,矩阵规模为$\mathbb{R}^{n_u\times n_r}$,这样我们就得到了word-level的相似度矩阵表示。
接下来,我们要获得segment-level的相似度矩阵表示,论文的处理方式是把它俩塞到一个GRU里去(这个操作在模型中没有表现出来),把它们分别转换成隐层的state,再用与上面相同的处理方法来计算出相似度矩阵,这个矩阵就是segment-level的矩阵相似度表示结果。
最后第三步,我们要提取文本中影响比较大的特征。到了这一步,我们已经拥有了每个utterance与那个被选中的response(the chosen one!)的multi-level的相似度表示,分别是word-level与segment-level的相似度,现在我们把它们当做CNN的两个channel进行卷积与池化,这一步的目的是为了剔除影响不那么明显的特征,保留影响大的特征。
Matching Accumulation
我们现在拥有了各utterance与那个候选response的关键特征,因为获得的是CNN输出,首先把它们拉成一维的形式。然后,我们 再放到GRU里进行encoding!!!(万能GRU系列,it’s so cooooooooool) ,这么做的目的同样是为了让每个utterance的特征能够影响到其它所有的utterances,另外还能保留utterances之间的时序信息。
Matching Accumulation
最后一个步骤,就是合并上面那个GRU的输出了,论文里给出了三种合并的方式,一种是直接取GRU最后那个state的输出,把前面的东西全部抛弃掉,一种是对所有的state输出进行加权,权重是随机分配的,最后一种好像是用attention机制来对每个state进行动态复权(说实话最后一种我怎么没看懂,所以我就不进行展开论述了),反正选择了输出的最终vector之后,使用了最小化交叉熵的形式对softmax参数进行了学习,最终就是通过softmax函数来输出对这个response的最终评分。
模型的效果
论文使用了Ubuntu Corpus数据集对模型进行了测试,另外因为’The Ubuntu Corpus is a domain specific data set’,作者们另外自己手动爬取并标注了豆瓣里面的数据,产生了’open domain’的Douban Conversation Corpus数据集进行测试。文中也说明了这个数据集之于multi-turn conversation研究领域的重要性(反正很重要就对了!)。
具体地,论文中比较了:TF-IDF, RNN, CNN, LSTM, BiLSTM(以上baseline);Multi-view Model;DL2R;MV-LSTM, Match-LSTM, Attentive-LSTM, Multi-Channel(以上属于Advanced single-turn matching models),反正就是说明了我们提出的模型效果就是好,相比较于其他的模型提升非常显著云云。
另外,论文中测试了在Matching Accumulation中所使用的三种合并GRU输出的方式,然后说最后一种动态复权的方式效果会略好于前两者,但是所需要的空间与时间开销会显著增大 所以其实也并不建议我们使用 。
最后,论文通过一些其它角度对模型效果进行了进一步的论证:关于结果的可视化,关于模型组件的ablation,关于选择的上下文长度等等。
模型存在的问题
鉴于我并没有能力与胆量就这篇论文提出问题,这部分是引用了论文中’Error Analysis’与’Conclusion and Future Work’部分:
- 逻辑一致性:SMN模型主要关注与上下文与response之间的语义层面的信息,但是几乎没有关注logical consistency层面的信息。也就是说,有时候虽然我的回答是与上下文相关的,但是在逻辑上面其实说不通,会导致别人头上产生三个问号然后conversation迷之中断这样。对于逻辑前后连贯的检索模型的研究是很有必要的。
- 一开始retrieval到的候选response中根本就没有正确答案:因为SMN模型实则是对retrieval到的候选response进行了一个打分排序,然后选择了分数最高的作为最后一个提问的回答,如果一开始的responses中根本就没有正确答案,那么这一切就很尴尬了。所以对于检索准确性的提升也是很有必要的。