论文的立意是在 联邦学习\ 过程中,结合 对比学习\ ,用局部与全局的两种 蒸馏\ 方式来 无监督\ 地学习样本的向量表示,阅读下来的感觉是与其说FedX是一种新的算法/模型,更不如说它是一种用于扩展在传统对比学习的无监督损失函数。
关键词:联邦学习(Federated Learning),对比学习(Contrastive Learning),知识蒸馏(Knowledge Distillation),无监督学习(Unsupervised Learning)。
联邦学习的整体流程如下图所示:

其中:
- Local Update:每个client各自学习自己的样本表示,获得各自独立的本地参数模型;
- Local model update:将本地参数模型上传到中心服务器;
- Global aggregation:中心服务器对所有client上传的模型进行聚合,最简单的方式是(假设本地模型都是同构的)根据client各自拥有样本数量的占比进行加权平均;
- Global model download:每个client将global model各自下载到本地。
论文主要聚焦的是步骤1。
以SimCLR为例,传统对比学习的损失函数如下所示:
其中,$B$与$\tilde B$分别表示原批次的训练样本,与进行了数据增强后的训练样本,即从一个真实样本中采用窗口看到的某个截图; $sim$ 表示某种对两个向量的相似性度量方法(比如余弦相似度,值得注意的是,作者在论文中也提到了余弦相似度,不过在实际的代码实现里用的是两个正则化(torch.F.normalize)后的向量内积), $\tau$ 类似知识蒸馏中用于控制程度的超参(temperature)。
整个函数的目标是:对于样本 $i$ ,已知模型最后一个隐层对于它的向量表示 $z_i$ ,及其增强后的样本 $\tilde{z_i}$ ,希望两者的向量更加接近,其相似度更高;而对于两个批次中其他 $2n-1$ 个负样本,希望其向量相似度越低。
在此背景基础上,论文提出,在本地模型更新时,除了每个样本和自己的增强后样本进行对比学习,两者还可以从彼此的分布中进一步学习,谓之为 关系损失(relational loss) 。特别地,给定:
公式(2)表示了正样本 $i$ 的隐层向量 $z_i$ 对于一个随机采样的批次 $B_r$ 中任意一个样本 $j$ 的隐层向量 $z_j$ 的概率分布。与之对应,正样本在对比学习中的增强样本隐层向量 $\tilde{z_i}$ 与后者也会有一个对应的向量分布:
作者提出的关系损失理念是:如果模型真的能辨认出增强前后的样本归属于同一个样本(或者标签),那么,除了对比学习本身设计的目标——这两个样本间的相似度高于同批次中其他负样本的相似度——以外,这两个样本对于某个随机的负样本的相似度分布函数也应该相似。
但是这个相似度要怎么度量呢?作者提出将这两个概率向量相加作为两者要学习的目标,即:
其中$KL$指的是KL散度,也即相对熵(其实就是真实分布不是one-hot前提下的交叉熵)。
正如上面所述,这个损失函数最小化的目标是两个概率分布对于其分布均值之间的距离。举个具体的例子,比如正样本及其增强分别代表下图中的同一只狗的两种不同的视角:
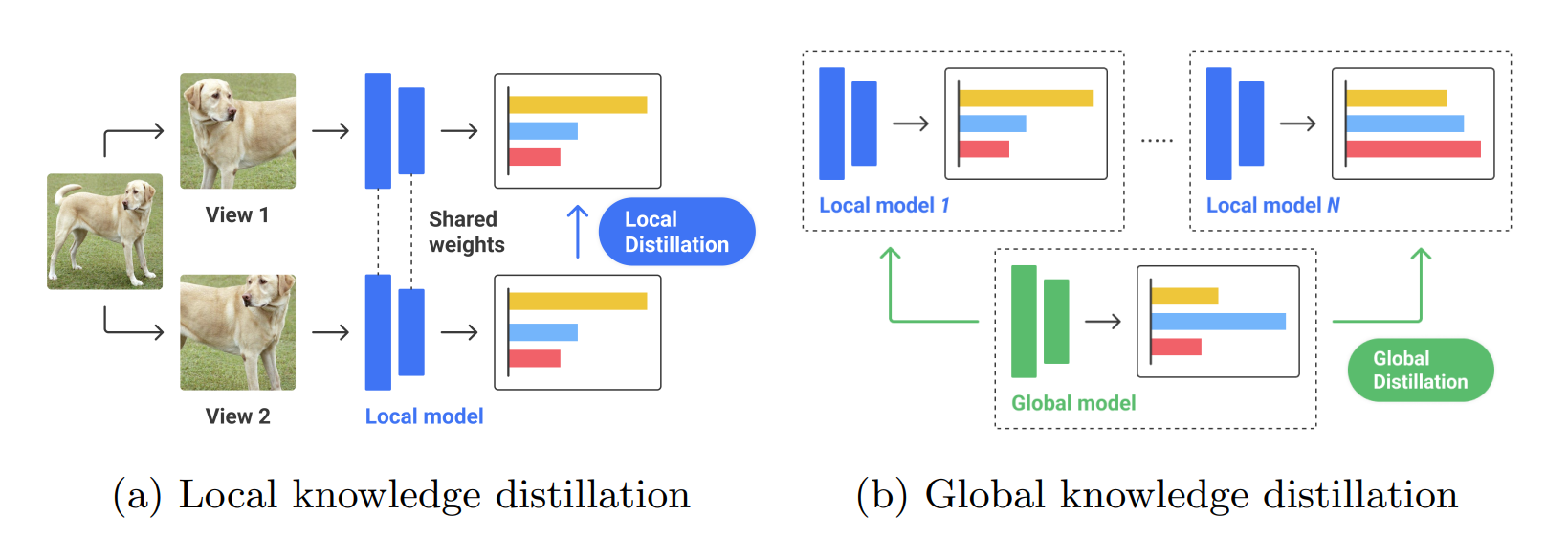
那么,对于另一个随机采样的样本(比如猫的某个视角),正样本的向量和随机采样样本的向量的相似度,预期上应该是低于正样本的向量和另一张狗的随机采样样本的相似度的;而作为正样本的增强样本,它对于不同的随机样本,也应该具有这样相似的特性。
最后,将对比学习的损失函数与关系损失函数加和,得到了联邦学习的步骤1中的最终损失函数:
除了局部的损失函数外,作者也引入了全局的损失函数,出于这样的考虑:模型不但要从自己独立的样本中来学习分布,自然也要从全局模型中学习信息,所以在全局上提出了与式(6)类似的全局损失函数。唯一的差别在于,全局损失函数的关系损失函数中,随机采样的负样本的表示向量从全局模型中取得(此时全局模型的参数是不冻结的,只用于提供特征向量)。
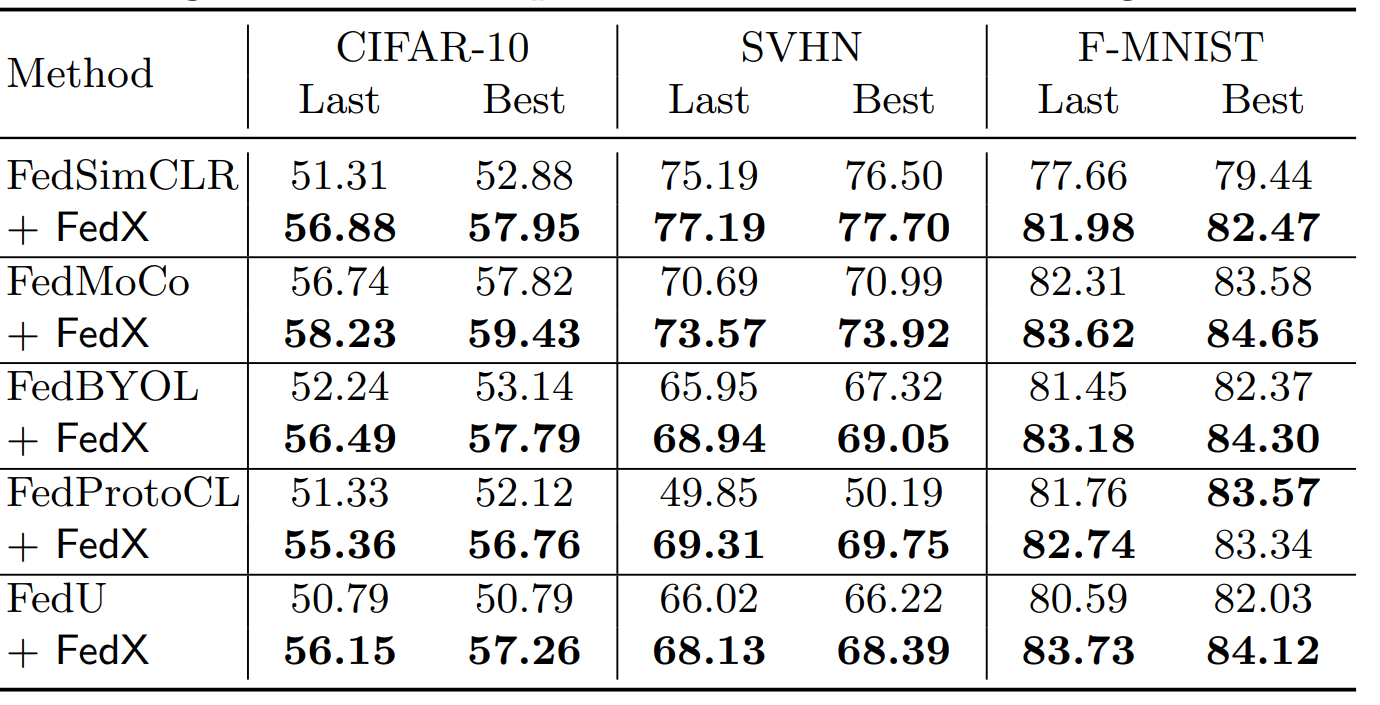
作者在CIFAR-10,SVHN,F-MNIST三个数据集上进行了实验,使用Dirichlet分布模拟联邦学习中各个client分得的样本分布,采用了SimCLR,MoCo,BYOL,ProtoCL,FedU一共5个方法作为基线模型,将各自加入关系损失后的+FedX方法作为提出的方法,在三个数据集上分别取得了4.29pp, 5.52pp和1.58pp的增长。
此外,作者也进行了一系列的有效性实验(在此不再赘述)包括:
- 验证模块有效性的消融实验(本地关系损失函数+全局关系损失函数+一个额外添加的两层全连接层变换) ;
- 参数敏感性实验:控制不同的数据量,不同的client数量与不同的本地-全局模型交互次数;
- Embed空间:全局模型与局部模型向量间的分布情况,预期上类内更加相似,类间更加不同。
最后,作者也提出了将FedX扩展到半监督学习的场景中的设定,在这个场景下,首先用未标注数据对模型进行参数的初始化,然后再在模型上层添加一个全连接层,使用标注数据再额外训练一定的轮次做微调。