1. Preface
KDD 2022,唐杰老师课题组的paper,主要讲了一种用transformers结构来做KGe (Knowledge Graph embedding) ,以在知识的复杂逻辑查询中有比较好的表现。
论文有几方面的亮点:
- 把KG里面的节点关系(relation/edge)转换成了关系节点,从而把两个节点+两者的关系变成了一个三元组。文中称之为 Triple Transformation Method;
- 使用了两阶段pre-training。第一阶段主要是通过两种Random Walk来对整个图进行随机采样,然后进行训练;第二阶段是通过预定义的一些范式(1p/2p/3p/2i/3i)来采样并训练;文中分别称为Dense initialization与Sparse refinement;预训练的任务与BERT相类似,都是通过mask其中若干节点,并要求模型预测这些节点;(值得注意的是,在二阶段pre-training与整个fine-tune过程中,也会mask若干节点,但只要求模型预测出最终节点);
- 在Multi-Head Attention上层训练多个FFN,以模拟出多专家投票的效果,来增大模型参数量;使用Gating的方式控制每次只选择2个FFN产出结果,以节省计算时间。文中称之为Mix-of-Experts(MoE)。
文中提出的这些方法使得kgTransformer具有以下优势:
- 动态的KG embedding(因为使用了transformer,此处可以参照GloVe embed与ELMo embed);
- 模型的学习过程与应用的目标是匹配的(这句话是针对部分模型,训练目标是补全一阶的graph relation link,而应用到多跳的逻辑查询)。
2. Introduction
2.1 Complex Logical Query
本文主要解决的问题是复杂逻辑查询,包括:补充边(imputed edges)、多源的实体、Existential Positive First-Order(EPFO)逻辑,以及未知的中间实体等。下面是EPFO的一个示例:
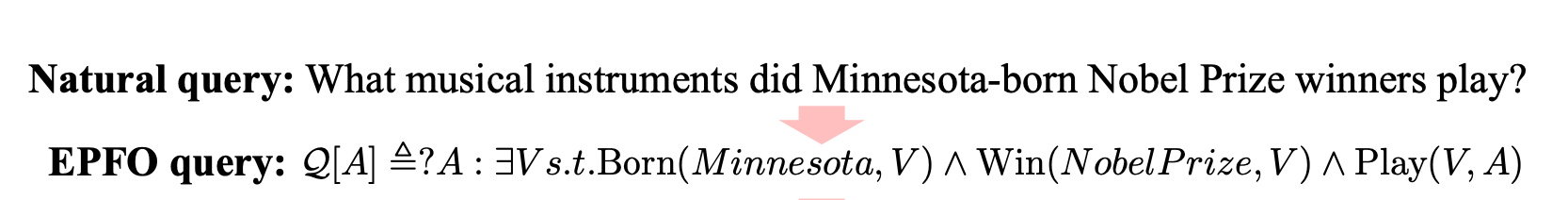
具体地,对于一句自然语言:
What musical instrucments did Minnesota-born Nobel Prize winners play?
所解析得到的EPFO查询,里面蕴含了一个若干约束的二跳(2-hop)知识图谱查询:
- 第一个约束是查询一个实体,出生在Minnesota;
- 第二个约束是查询一个实体,获得了诺贝尔奖,与上一个约束指向同一个实体;
- 第二跳是查询上面得到的实体所Play的乐器。
可知,第二跳的查询结果才是问句所想要得到的答案。
此类EPFO查询的难点在于:
- EPFO查询的解析复杂度与hop之间的关系是指数级的;
- EPFO查询要求模型具有比较强的迁移与泛化能力。
2.2 Contributions
论文的贡献在于:
- kgTransformer: 提出了kgTransformer,使用Triple Transformation策略来将知识图谱带有属性的边(relation)转换为不带属性的有向边;提出了MoE来顺应GNN稀疏激活的特性。
- Masked Pre-Training: 为了提升泛化能力,作者将复杂逻辑查询问题看作一个预测mask的问题,通过两阶段预训练来训练模型;在FB15k-237与NELL995两个数据集上进行了验证,说明了模型具有SoTA的效果。
3. KG Pre-Training Framework
3.1 kgTransformer
kgTransformer主要思想是把图作为sequence,放到transformer里面进行预训练与微调。为了实现这个目的,首先需要进行数据的准备。
怎么将图转换为序列呢?节点之间的邻接关系可以通过random walk的方式获得,但relation edge带有的属性不好嵌入到这样的结构中去。所以作者提出在做数据准备的时候,把所有的relation edge也转换成节点加入的图中,而由relation node所连接的两个entity node,所使用的边都是有向边。
值得注意的是,在这样的图里,实体节点与这个关系节点是需要做类型区分的,作者在transformer的输入层加入一个特殊的node type embedding来实现了这个目的。
文中所使用的transformer大体结构及其内部公式与 Attention Is All You Need 是一致的,只是sequence中每个token从原来的文字变成了现在的节点。在encoding的时候,通过Multi-Head Attention来计算得到每个节点相邻节点与它的关系重要程度,并通过FFN来进行变换得到最终输出。
有一点与transformer不一样的是,对于MHA上面的FFN,作者初始化了多达32个(实际实验中选择的数量)FFN来进行学习,以模型专家投票的机制,称为Mix-of-Expert(MoE)。
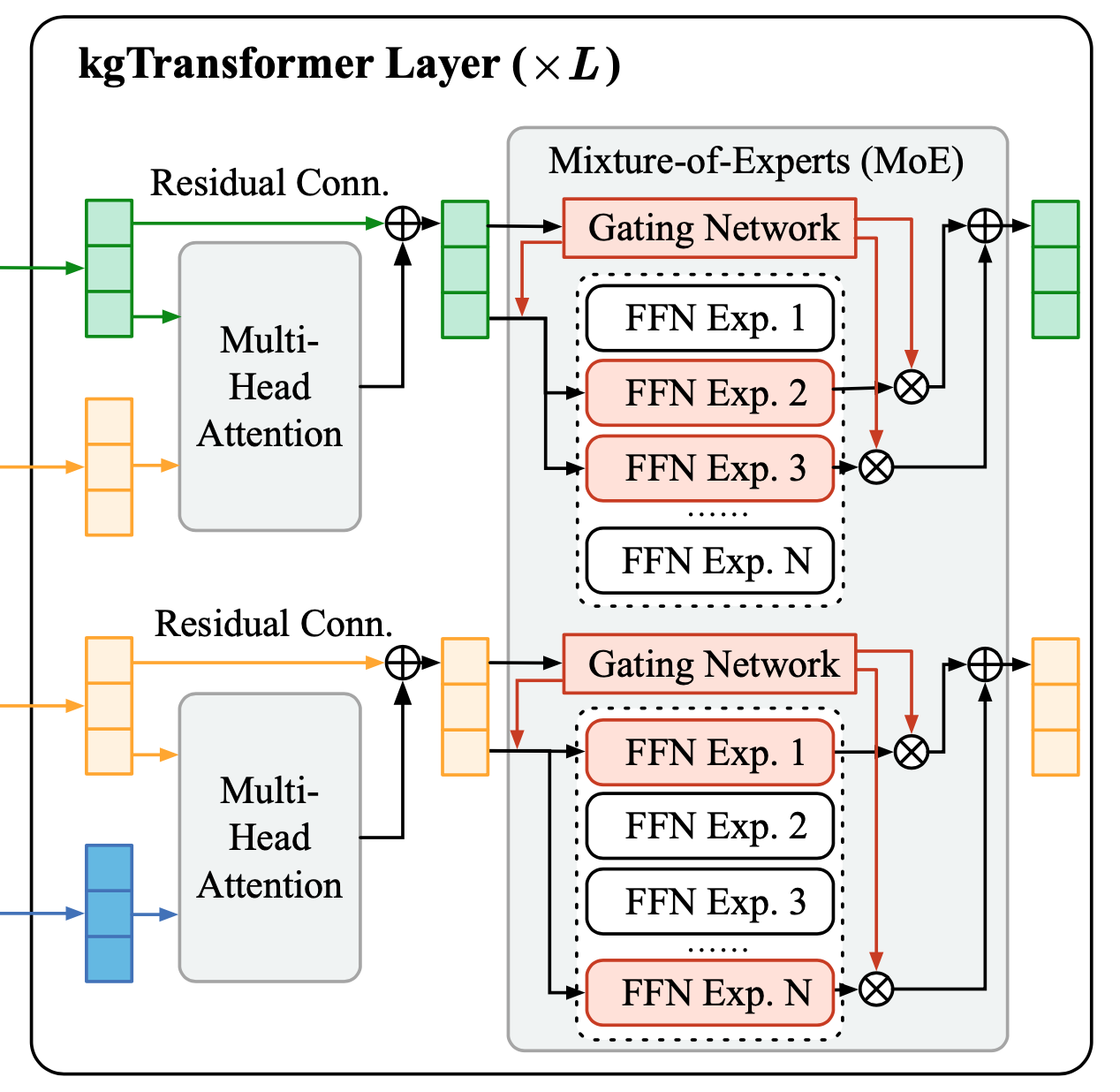
- 在训练时,门控机制只会选择权重最大的两个FFN,将其输出进行求和作为最终输出,以保证训练过程中的时间不过长;
- 在预测时,不使用门控机制,将所有的FFN结果求和作为最终输出。
为什么加入这样的MoE会让效果变好呢?作者提出:在transformer中,已经有研究发现FFN与key-value network效果是等同的,即FFN通过全连接的方式实现了与attention类似的效果,其全连接的权重可以从侧面被看做是输入间的重要性关系。因为这个原因,transformer里FFN输出的元素里大部分都是0,是很稀疏的。在此基础上,作者也做了一些前置研究,发现EPFO里的FFN一般只有10%-20%的神经元被激活(除了最后的decoder层)。正因为有稀疏性的存在,作者认为使用MoE,把一个很大的FFN分解成若干个小的FFN,能够更好的增强模型泛化能力。
3.2 Masked Pre-Training and Fine-Tuning
在定义kgTransformer的结构与输入数据模式之后,开始进行模型的预训练与微调。作者又把预训练分为了两个阶段,在第一个阶段,使用随机游走采样出不同的子图,进行模型的初始化;在第二个阶段,使用预先定义好的一些meta-graph结构继续预训练。
为什么要分成两个阶段进行预训练呢?作者认为,第一个阶段是尽可能将KG中的知识嵌入到模型中去,在此时采样窗口一般会设置得比较大,采样结果是稠密(dense)的,并且追求采样出来的子图的多样性,从而让模型见识尽可能多的pattern;但是,在实际应用时,大部分的逻辑查询结果是稀疏(甚至out-of-domain)的,而只进行第一阶段的预训练,会让模型的迁移能力变差。
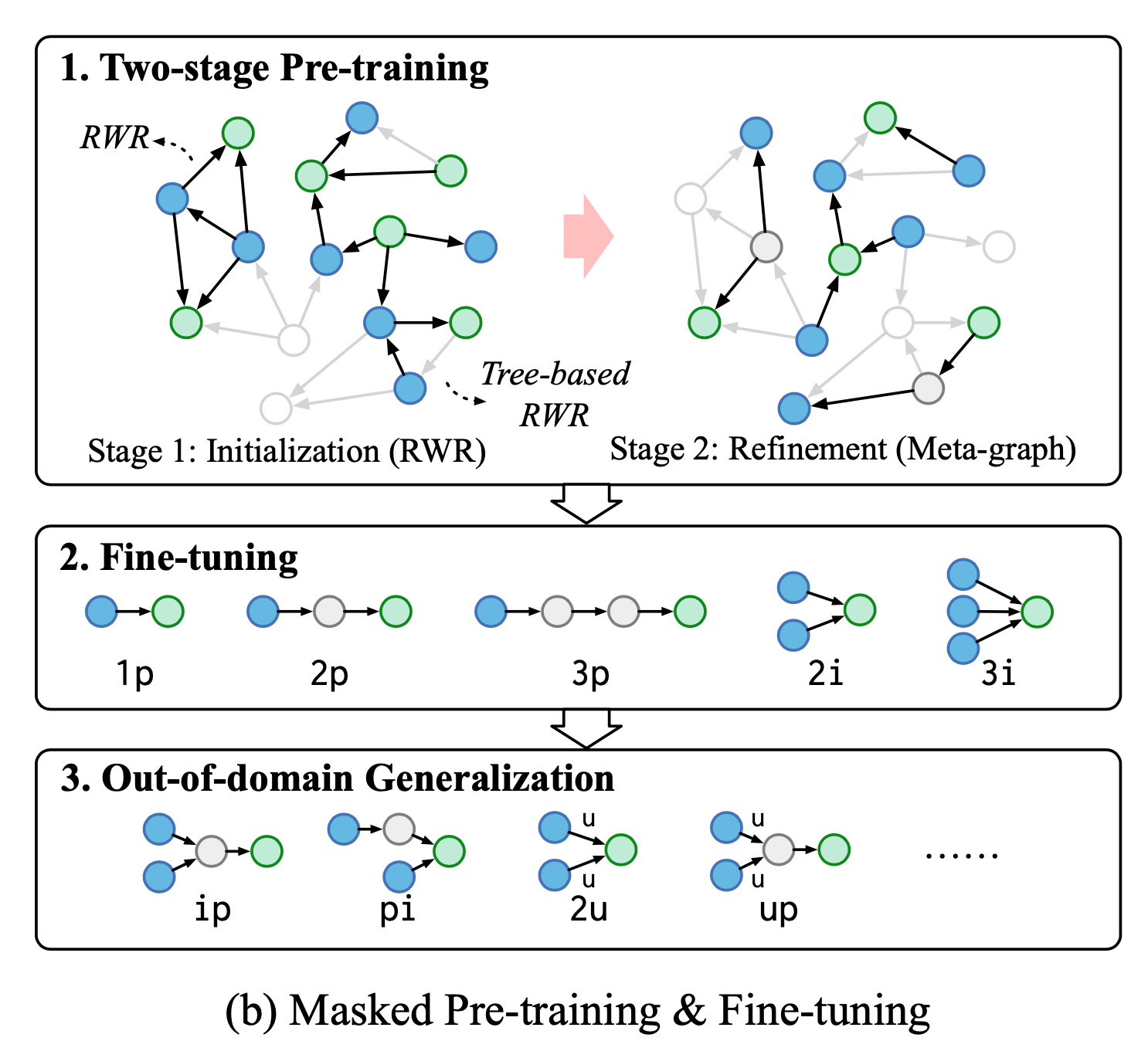
2-stage pre-training
在预训练的第一个阶段:dense initialization,作者使用了两类随机游走的策略对原始图像进行采样,分别是 random walk with restart (RWR)\ 与 tree-based RWR\。专门加入tree-base是因为EPFO的逻辑连接关系更像是树状的结构。
设kgTransformer内部参数为 $\theta$,随机mask的实体集合为$\varepsilon_{mask}$ ,随机采样后的子图原始输入为 $X=[x_{e_0}^{(0)},…,x_{e_T}^{(0)}]$,mask之后的子图输入为$\hat{X}$ ,第一阶段dense initialization的学习目标是最小化损失函数:
其中 $A$ 表示节点之间的邻接关系,是由随机游走采样得到的。
在预训练的第二个阶段:sparse refinement,作者使用了基础的EPFO pattern: $1p,2p,3p,2i,3i$ 作为meta-graph,保证每个子图中不会包含超过4个实体,随后仍然采用mask的方式让模型预测mask前的entity embedding,但在这个阶段,模型只会最小化所有目标实体的损失函数,即:
fine-tuning
尽管预训练的第二阶段已经比较接近于想要解决的任务,但作者发现使用目标数据集进行fine-tune仍然是比较重要的(原文附录表2中进行了论证);此处的训练目标是最小化所有可行解的损失,给定一组可行的答案$\varepsilon_A$,微调阶段对于每个查询的损失函数记为:
其中加入的$\exp$意为这是softmax的最终输出,整个式子要求所有可行实体的softmax输出概率之和尽可能大。
此外,作者注意到最近的NLP研究指出多任务学习能够有效避免模型过拟合,且从彼此的训练过程中受益。因此作者首先在所有的任务中进行了预训练,随后逐个在不同的任务中进行了微调。而在out-of-domain的泛化中,部分pattern是由几个meta-graph查询组合得到的,对于这些特殊的pattern,作者采用了一个比较tricky的分解预测的方法,分别求得子查询的结果后,将其概率转换为概率排名,取第一名作为最终的预测结果。
4. Experiments
作者在FB15k-237与NELL995两个数据集的9个reasoning任务(包含了in-domain与out-of-domain)中测试了kgTransformer的泛化能力,结果如图所示:
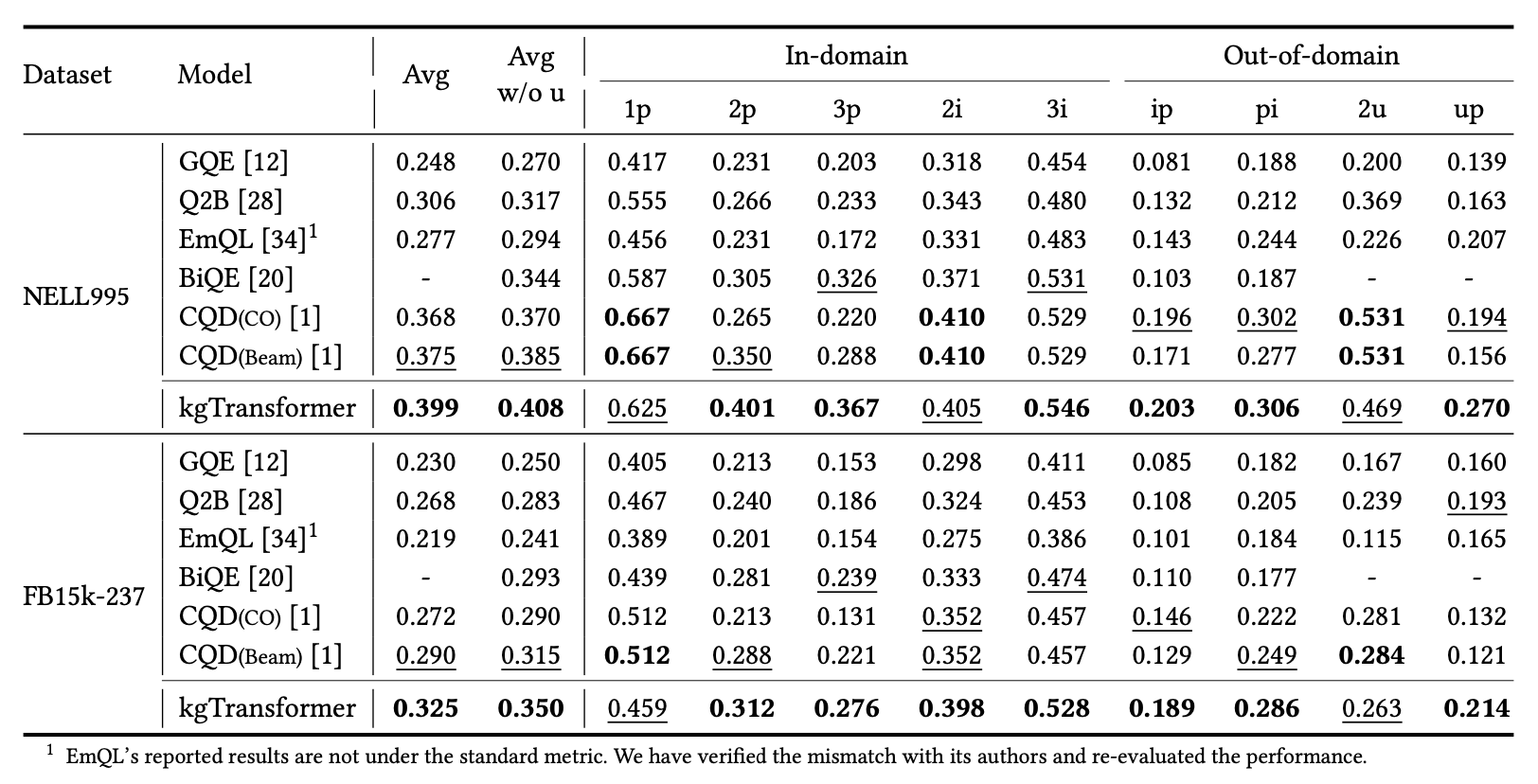
其中加粗部分为所有实验中效果最好的,下划线部分为实验中效果次好的。可以发现,与此前的SoTA方法CQD相比,作者提出的kgTransformer在NELL995上取得了绝对值2.4%(相对值4.6%)的提升,在FB15k-237数据上取得了绝对值3.5%(相对值12.1%)的提升,提升效果比较显著。
作者对kgTransformer的组成方法:2-stage pre-training与fine-tune进行了缺省实验,结果如下所示:
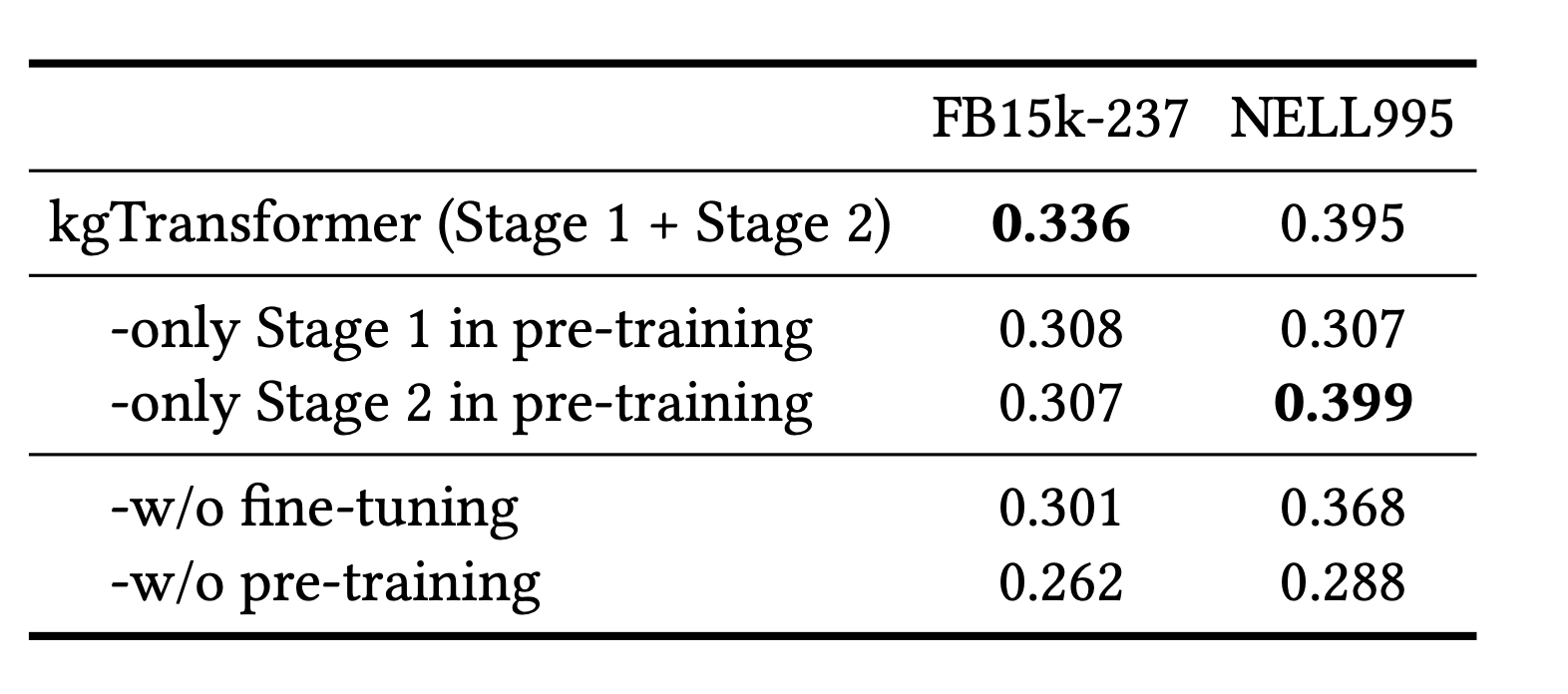
作者发现,pre-training与fine-tuning作为模型的训练过程都是十分重要的,不管缺少哪一个部分,都会带来非常大的效果下降。而对于pre-training过程中的两个阶段,其中第二个阶段对于FB15k-237几乎没有影响,而给NELL995带来了显著的提升。考虑到sparse refinement的提出动机,说明NELL995中的稀疏pattern更多。
对于MoE的效果,论文进行了不同数量MoE下的性能与模型效果比较,证明了使用合适数量(实验中为32个)的Experts+Gating机制,能够给kgTransformer带来16倍的size提升,而实际的计算成本只增加了11.6%-38.7%