1. Preface
张拳石老师的一作,发表在PAMI上的论文,最近买了他参与编著的《可解释人工智能导论》,正好又在Arxiv上看到了这篇文章,就拿来学习一番。
文章主要目标是以信息论为基础,解释知识蒸馏为什么能让学生模型比一个从头学起的新模型效果更好的原因。为了更好地阐述新的概念,作者首先提出了知识点 Knowledge Point (下文有时将其简称为KP):KP指的是样本中的一组输入单元(input unit),相对于其它的输入单元,在DNN中它的信息损失明显地更少。在文中先给出了KP的公式化定义,随后,作者提出了三个假设,并对应地提出了三个评估指标来验证它们。
- 通过知识蒸馏学出来的模型,所包含的 有效KP\ 更多;
- 知识蒸馏的学习过程会让学生模型 同时学习多个KP\ ,而从头开始训练的模型是序贯地学习KP;
- 知识蒸馏学习开始时,学生模型相比于从头训练的模型 优化更加稳定\ 。
个人视角下,文章具有的几个优点:
- 文章具有较强的创新性。除了提出一种新的视角来看待知识蒸馏以外,其实知识点这个思路完全能够被使用在传统的DNN分析上(事实上,作者在论文的结尾部分也尝试使用了KP来解释模型的fine-tune过程,不知道未来是否会有进一步的研究发表)。
- 实验翔实,3个评估指标 * 3类实验,作者都一一给出了实验结果与对应的分析;同时,对于文中几乎所有的解释,作者又会附上补充实验加以验证。
- 贯承期刊的风格,这篇文章的结构组织比较清晰,阐述逻辑冗而不杂,阅读的时候基本没有遇到障碍,给个好评。
这或许也说明了想要清楚地解释人工智能,首先需要的是清楚地解释自己的解释。
最后,考虑到我们一般把知识蒸馏过程中的两个模型叫做teacher network与student network, “知识点” 这个翻译实在是有点奇妙的韵律感,让我不禁联想到考试前,老师给学生划重点的熟悉场面 “重点?我讲过的都是重点” 。
2. Introduction
尽管知识蒸馏在图像分类、3D分割,NLP等诸多领域都有了长足的应用,迄今为止对于知识蒸馏为何有效的研究却并不算多。相关的文章主要有:将蒸馏认为是对训练样本的重赋权1、认为是对部分重要信息的学习2,其效果近似于标签平滑3以及快速收敛4等。
基于信息论,这篇文章提出了另一种认识知识蒸馏有效性的方式:量化深度模型学到的知识点(Knowledge Points)。特别地,给定一个模型与一个特定的样本,作者量化地定义样本中的KP为:输入单元中没有显著信息损失的部分(经过模型以后)。如下图所示,在一个图像分类任务中,对鸟进行分类时,模型往往会关注鸟类的翅膀作为一个KP。

通过对于知识点的量化,文章首先关于知识蒸馏为何会有效,提出了三点假设。
首先:知识蒸馏使得DNN能够学到更多的KP。信息瓶颈理论5 6认为一个深度神经模型倾向于保留与任务相关的特征,并且忽略掉那些和任务不相关的特征。在知识蒸馏中,一个教师模型往往能够编码与更多任务相关的KP,而由于学生模型在蒸馏时尝试模拟教师模型的输出,所以相较于一个从头开始训练的模型,也能够保留更多与任务相关的KP。
其次,知识蒸馏让学生模型能够同时地学习KP。因为知识蒸馏的过程会让学生模型同时去模拟教师模型所编码的所有知识点,在第一个epoch时候就喂给它所有的有效信息。
最后,知识蒸馏让学生模型的优化过程更加稳定。一个从头开始训练的DNN,在训练的开始阶段,会去尝试各种可能对任务有帮助的KP,在一定时间后收敛到真正有帮助的KP;而知识蒸馏在最开始,教师模型就把所有的有效KP告诉了学生模型,从而让后者少走弯路。特别地,作者把前面的现象称之为 detours\ 。
为了验证这三个假设的正确性,作者进一步提出了验证它们的评估指标:
- 统计模型学到的KP的质量(quantity)与数量(quality);
- 模型学习KP的平均速度(不同的KP是否是以相同的速度被学习);
- DNN在学习过程中是否经历了 detour 。
值得注意的是,作者特意指出了这篇文章分析的范围与前置条件:
- 作为让后续实验更加公平的必需条件,知识蒸馏所使用的教师模型一定是在目标任务上进行了很好的调试;
- 知识蒸馏一般有两种应用方式,第一种是对模型接近输出层的中间层输出进行学习(一般是高维的特征),这种情况下学生模型会去尝试学习教师模型所编码的实际知识;第二种是对模型softmax之前的输出进行学习(一般是低维的特征,和label size相同),这种情况下学生模型只会去挑选。
总的来说,这篇文章有以下贡献:
- 文章中所提出的知识点的概念是一种全新的分析DNN的视角;
- 以知识点为基础,提出了三个评估指标来解释知识蒸馏的机制;
- 提出了知识蒸馏有效的三个假设,并在多种类型的实验(图像分类,三维点云分类,二元情感分类,问答)中进行了验证。
3. Hypothesis & Metrics
这部分主要阐述文章的主要部分:关于信息损失的详细定义,从而引出知识点这个概念;通过知识点的概念详细解释3个假设,以及如何设计指标去进行量化的评估。为了行文通顺,这部分不会苛求与原文的结构一致,以能够将概念解释清楚为准。
3.1 信息损失与知识点
3.1.1 信息损失(information discarding)
基于信息瓶颈(information-bottleneck)理论,作者提出将DNN里的前向传播过程看作是对输入的 信息丢弃(information discarding)的过程,如果模型有多层,每一层都会丢弃掉一些信息。在底层中,大部分的输入信息都会用于特征计算,而在高层中,只有少数真正与模型推理相关的特征会被用于特征计算 —— 大部分的对任务没有帮助的信息在这个过程中被丢弃了。
那么,怎么去量化在模型前向传播过程中,某个输入单元被丢弃了多少信息呢?作者在这里quote了自己课题组之前发表的两篇文章7 8,旨在说明 对模型的某一中间层做一个独立同分布的扰动,其对模型最终输出的扰动会小于该扰动乘以一个常量 。这里会稍有些难以理解,作者使用的式子(这里稍作了点变动以更好的理解)为:
其中 是普希茨常数(Lipschitz constant)。式子表示的含义为:对于两个不同的输入特征 以及模型的中间层对它们的特征表示 ,模型的最终输出 差距是有一个理论上限的,其上限不会超过它们中间层特征的差距乘以一个常数。
为了便于后续的实验,作者在这里把这个式子进行了延伸,把右边的 中间层差距 改为模型 原始输入特征 的差距,即:
这样有什么好处呢?在上式中 代表的是两个不同的输入样本,也可以代表 原始样本\ 与 添加了扰动之后的样本\ 。由此,因为给模型输入添加扰动以后,其输出的扰动是存在上限的,我们可以给模型的原始输入添加扰动,然后观察这个原始输入的输出变化情况。由此,我们进一步定义熵 来表示给原始样本添加扰动以后,一直到让模型改变对这个样本的预测结果之前,究竟有多少信息可以被丢弃:
这里的 是常数 中的一个参数,也可以视为一个常数。
由于样本的输入特征是一个集合(比如图像的输入特征是像素点的集合),我们给每一个特征添加一个 独立同分布的高斯噪声\,这样原始样本的整体扰动 又可以被解构为样本中每一个特征添加的扰动之和:
其中表示样本的特征数,基于最大熵法则,我们能算出每个像素点在给定扰动下的信息损失值:
至此,我们成功的量化了每一个像素点(以图像分类任务为例)的信息损失 ,这对我们后续定义知识点至关重要。
3.1.2 知识点(knowledge points)
在正式定义知识点之前,首先给出两个概念:前景\(foreground)与背景\(background)。对于图像而言,前景与背景定义十分明晰。很多实验都已经表明,对于一个图像分类任务而言,背景的特征重要性相对而言远小于前景(比如辨识不同的鸟类,可以看它们的毛色/翅膀形态,但看天上的云帮助就不大)。基于此,作者首先提出,对于其它没有明确前背景概念的任务(如NLP)而言,前景指代会对任务分类有帮助的特征集合,而背景表示对该分类任务没有帮助(或者帮助很小)的特征集合。
综合上面的阐述,作者提出 知识点 的公式如下:
其中, ,表示所有属于背景的像素点/集合的信息损失的期望值(对于某一次扰动也就是它们的平均值),而 是一个人为设定的超参数阈值。
整个公式对于知识点(KP)的定义是:这样的一组像素点/像素集合,在给样本添加高斯噪声后,它们的信息损失,超过了所有背景像素点/像素集合的信息损失的平均值,超过的幅度大于。

从个人理解的角度,这个公式其实具有很强的解释意义:给某个像素点加了扰动后,出现了超过一定阈值的信息损失,那么这样的像素点一定对于模型预测很有帮助,而以背景像素点为代表的其它像素点,即使添加了一定的扰动,也对模型最终结果影响不大,所以我们管前者叫知识点。
3.2 假设与评估
在了解知识点定义的情况下,可以回头重新来看针对知识蒸馏为什么会比从头训练一个模型更有效,作者所提出的三个假设。
3.2.1 假设1
假设1:相比较于一个从头开始训练的模型,知识蒸馏使得学到的DNN编码了更多的KP。
作者提出了两个评估指标来验证这个假设:
- 知识点的数量
- 知识点的质量
对于知识点的数量的定义十分明确:给定一个训练后的模型与一组样本,添加扰动后,所算出来的该模型对于样本的知识点的数量的平均值。但如何评价知识点的质量呢?
作者认为,我们观察到的一个结论是:如果一个知识点处于前景,这个知识点对于模型做分类任务会很有帮助,而如果一个知识点处于背景,相对而言帮助就没那么大。所以作者定义 前景KP占总KP的比率 作为知识点质量的考察指标。
3.2.2 假设2
假设2:知识蒸馏使得(学生)模型能够同时学多个KP,而一个从头训练的模型序贯学习不同的KP。
这个关于并行串行的假设其实有点绝对了,在文中作者实际的论证点在于:知识蒸馏学习KP的速度会相对更快、更加\同时。
为了验证这个假设,作者提出的评估指标是:随着训练轮次的增长,学到的 前景 知识点是不是增长得更快(数量上+时间上)。容易理解:如果数量增长更快,说明知识蒸馏能够使得模型在同一时间学习更多的知识点;如果时间更快(即更快地达到了模型能获取到的最大知识点),说明知识蒸馏使得模型学习知识点的速度更快。
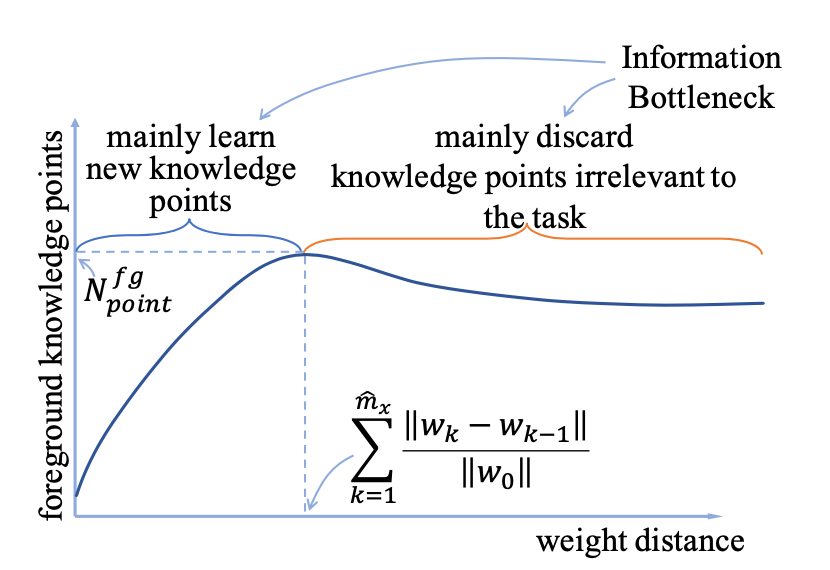
这里作者给了一个示例图,值得注意的是,作者实际使用的横坐标不是训练轮次(epoch数量),而是weight distance ,其中表示不同的训练轮次,表示第次的参数,表示能训练出最多的KP的那个轮次。使用weight distance而不是训练轮次作为横坐标的好处是:模型的参数往往会在开始的几个轮次里有比较强烈的变化,而后面的轮次里变化相对较小,所以使用weight distance能够更好的观察出前面的增长速率。
对于这样的一条折线,求出一直到最大轮次 时的均值 与方差 ,就能表示该模型在学习过程中的学习速率与稳定性。如果均值越低,说明模型学习知识点在时间上更快,如果方差越低,说明模型能够同时学习更多数量的知识点。
3.2.3 假设3
假设3:知识蒸馏学习模型的优化过程比从头学习的模型更加稳定。
直觉上,有了教师模型的帮助,一个学生模型会比一个从头开始训练的模型 更快地找到真正有用的知识点 ,而后者在训练的最开始往往会尝试更多的知识点,以此来确定真正有效的那一组。也就是说,有了知识蒸馏的帮助,学生模型会少走更多弯路,它在整个训练过程中所考察过的KP,会比从头训练的模型更少。作者基于此设计了指标:
其中,表示最终使用的模型轮次,表示第轮选择出来的KP集合。
值得注意的是,假设2与假设3中的所有KP集合都仅指代所有的前景KP,而不考虑背景的KP。
4. Experiments
在给定以上三个假设及其评价指标的基础上,如果假设均成立,我们应该观测到的现象是:
- 对于假设1:知识蒸馏后的模型(student model,下称S)的知识点数量会多于从头训练的模型(baseline model,下称B),且质量(即属于前景的知识点占总知识点的比值)优于B;
- 对于假设2:如果所有样本到达其最高知识点数目的weight distance均值越小,说明模型学习知识点的速度越快,而如果所有样本到的其知识点数目的weight distance方差越小,说明越多的知识点在接近的时间到达其稳定状态, 因此S的 均小于B;
- 对于假设3:样本到达其最多前景知识点的过程中,所出现过的全部前景知识点集合越少越好,即S的 会大于B。
4.1 实验细节
论文选择了三类不同的任务来验证所提出的假设:
图像分类任务
- 模型:AlexNet,VGG-11,VGG-16,VGG-19,ResNet-50,ResNet-101,ResNet-152
- 数据:ILSVRC-2014 DET,CUB200-2011,Pascal VOC 2012
自然语言处理任务 —— 值得注意的是,自然语言处理数据中的使用的
前景与背景
知识点是由人工定义的,即由人工来判断样本中某个token对于样本的结果是否有显著的影响。
- 问答:BERT+SQuAD
- 情感分类:BERT+SST-2
3D点云分类任务 —— 由于数据中没有提供背景,作者基于采样的方式手动构造了样本的背景。
- 模型:PointNet,DGCNN,PointConv,PointNet++
- 数据:ModelNet40
在考察蒸馏效果时,作者选择了顶层的CNN与所有的FC层。此外,作者根据不同任务的不同模型选择了不同的值:图像分类和NLP的大部分模型阈值设定在0.2,除了AlexNet设定在0.25,而3D点云分类任务的值设定在0.25.
4.2 实验结果
图像分类任务的不同模型效果如下表所示:
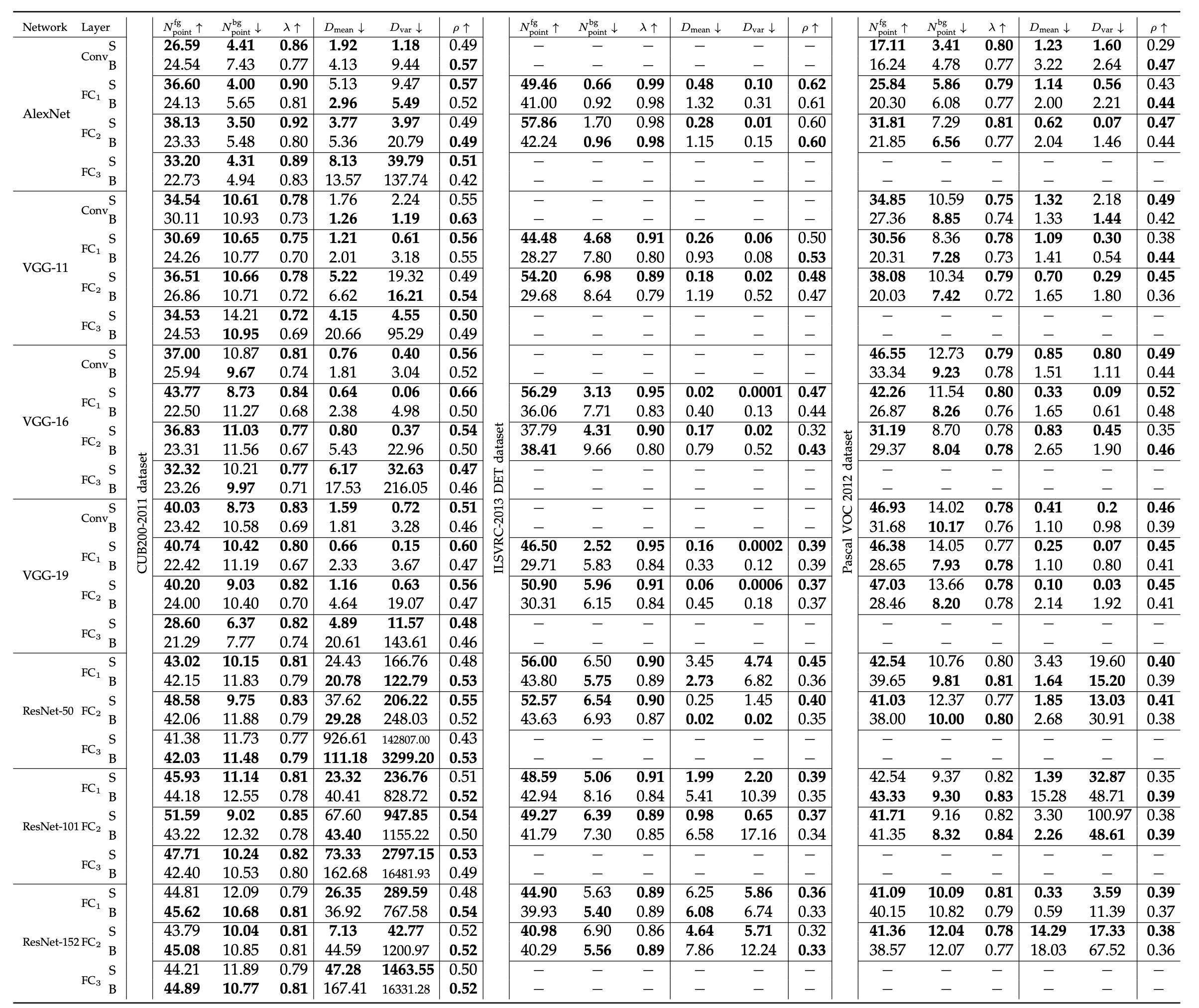
可以看到,在大部分的实验组别(以及同一个模型的不同中间层)中,基于知识蒸馏学得的S模型都优于B模型,说明学生模型确实能从知识蒸馏中获得相对更多的KP数量与更高的KP质量、获得更快的KP学习速率、经历更少的KP候选。
不过在少数的CNN中间层中,其经历的KP候选集(假设3)反而会高于从头开始训练的模型,作者认为这是因为CNN通常不会被充分地微调(对于预训练模型来说),因此其所在的教师模型反而会在其中嵌入一些噪声(比如模型用于预训练ImageNet中有许多域外标签),因此不满足作者在最初提出的条件:教师模型必须是在目标任务上进行了充分的调试(在这儿等着呢)。
为了验证这个分析是否合理,作者额外进行了一组实验,在Tiny-ImageNet上进行了微调,因为这个数据集有充足的训练集来使得CNN在微调过程中充分收敛。
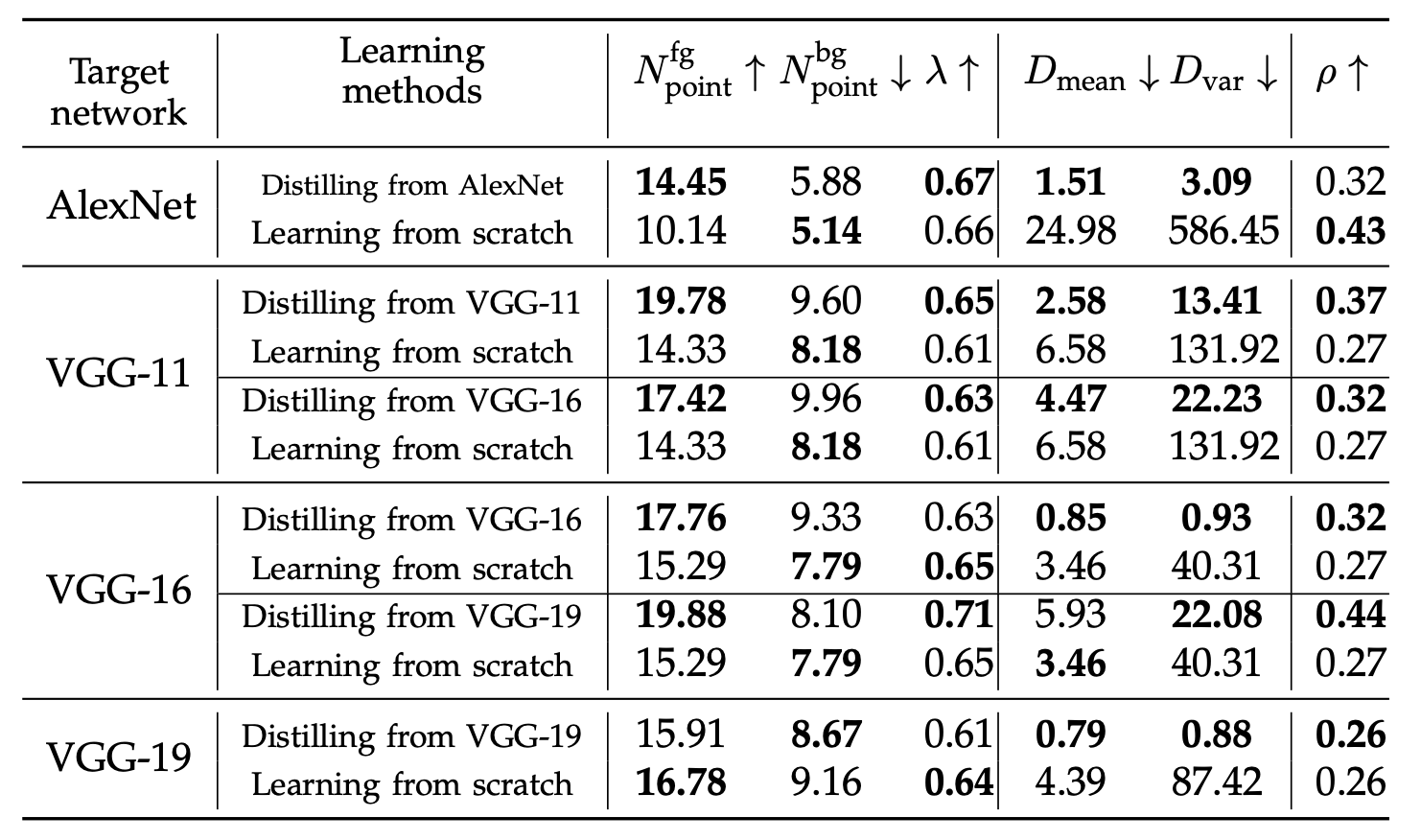
可以看出,在充分微调以后,CNN中间层也能满足假设3了。
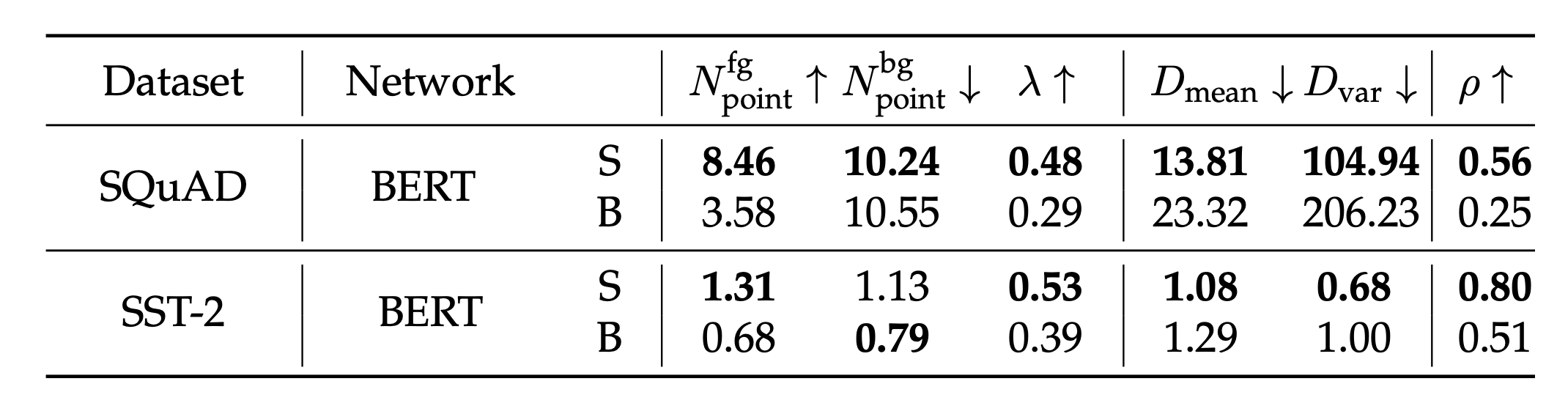
对于自然语言处理中的问答任务与情感分析任务的实验结果如下图所示,可以看到三个假设都能被满足,但在第一个假设中,尽管学生模型的前景KP数量与其KP质量均优于从头训练的模型,但其背景KP的数量在情感分析任务中也会大于从头训练的模型。
这种现象在3D点云分类任务中更加明显:
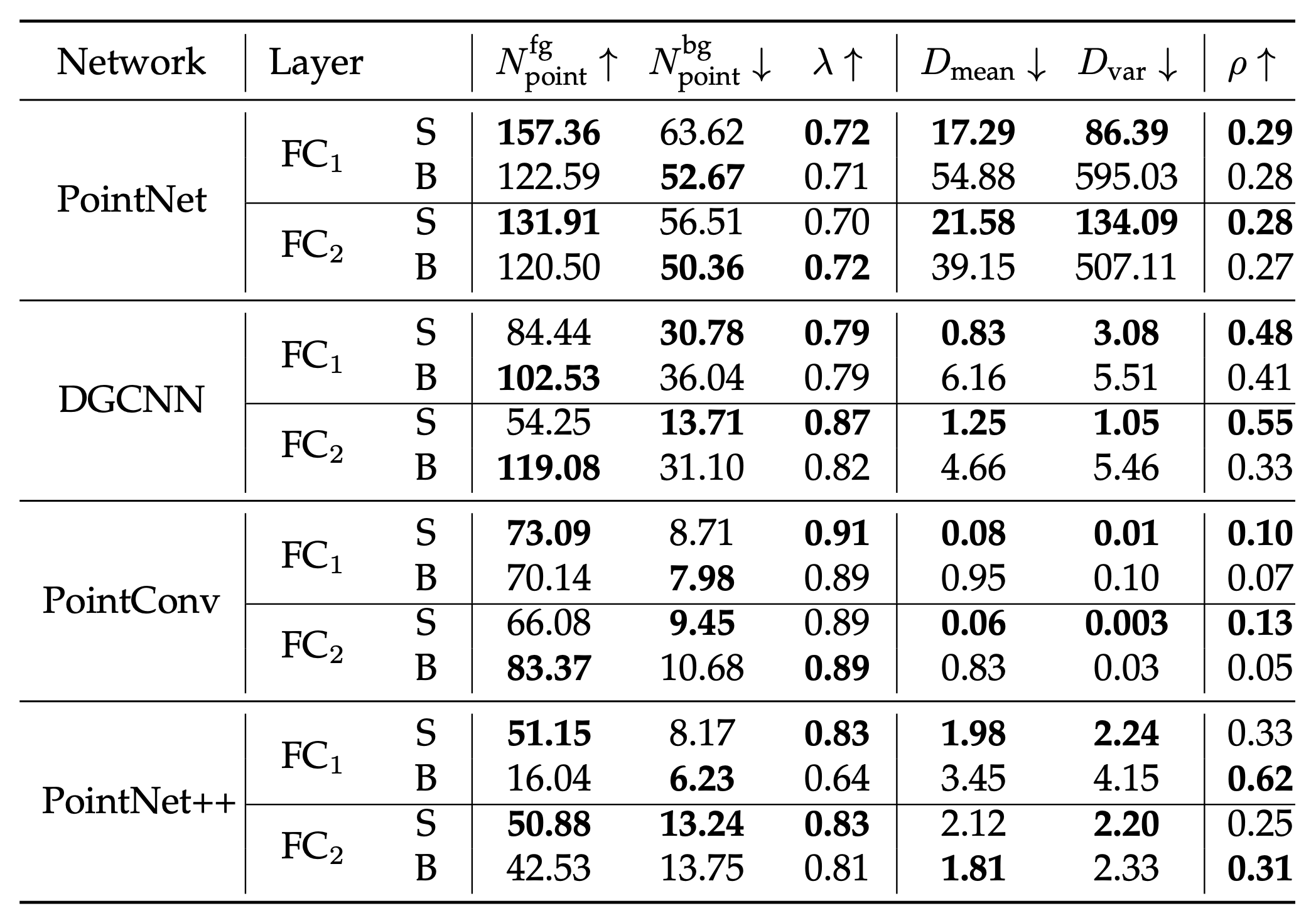
在满足作者所提出的3个假设的基础上,仍然可以观察到在相当一部分数据中,使用了知识蒸馏的学生模型的背景KP数量会比从头训练的更多,所以这个现象仍然有一定的普遍性。
这是什么原因呢?作者提出是因为这些模型在蒸馏时使用的是在大量数据上进行过预训练的大模型,而这些模型由于进行了充分的预训练和微调过程,往往会编码远超必需的知识点,从而导致下游的学生模型的背景KP也有所增多。但由于其编码的前景KP也相对变得更多了,最终的质量仍然显著优于从头训练的模型。
4.3 其它
比较有趣的一点是,在实验的最后部分,作者在fine-tuning过程中也使用了知识点进行分析,想要看看知识点是否对于分析一些传统的迁移学习方法有所帮助:从知识点的角度,一个模型的微调过程对模型产生了什么影响?

作者在VGG-16网络上通过Tiny-ImageNet数据集进行了fine-tune,并使用了一个从头训练的VGG-16进行对比,可以看到,fine-tune的过程使得模型在前景知识点上学习得更加迅速,并且不需要尝试过多的无用知识点(即满足了假设2与3)。
References
T. Furlanello, Z. C. Lipton, M. Tschannen, L. Itti, and A. Anandkumar. Born again neural networks, arXiv preprint arXiv:1805.04770, 2018 ↩
D. Lopez-Paz, L. Bottou, B. Scholkopf, and V. Vapnik. Unifying distillation and privileged information. In ICLR, 2016 ↩
J. Tang, R. Shivanna, Z. Zhao, D. Lin, A. Singh, E.H. Chi, and S. Jain. Understanding and improving knowledge distillation. arXiv preprint arXiv:2002.03532, 2020 ↩
M. Phuong and C. Lampert. Towards understanding knowledge distillation. In International Conference on Machine Learning, pages 5142-5151, 2019 ↩
R. Shwartz-Ziv and N. Tishby. Opening the black box of deep neural networks via information. arXiv preprint arXicv:1703.00810, 2017 ↩
N. Wolchover: New theory cracks open the black box of deep learning. In Quanta Magazine, 2017 ↩
C. Guan, X. Wang, Q. Zhang, R. Chen, D. He, and X. Xie. Towards a deep and unified understanding of deep neural models in nlp. In International Conference on Machine Learning, pages 2454–2463, 2019. ↩
H. Ma, Y. Zhang, F. Zhou, and Q. Zhang. Quantifying layerwise information discarding of neural networks. In arXiv:1906.04109, 2019. ↩