Facebook(Meta) 发表的一篇关于使用对比学习+多任务学习,增强推荐商品相关性的一篇文章,目前在Facebook Marketplace里A/B测试了两周,能够将用户-推荐商品的交互率增加4.5%。
有意思的一点是,这个一作哥们一次性在arXiv上挂了两篇文章,发表在不同的顶会上,起了类似的名字 名称+解释+facebook marketplace ,说明F家的线上值得介绍的新方法应用还挺多。 然而还是被美国马裁员了4/5,令人唏嘘。
文章一如工业界的行事风格,不整弯弯绕绕的理论分析,直接给方法+线上效果,有种简单有效的美。
文章的亮点在于,除了比较基础的对 <用户query,推荐商品> 使用对比学习来获得两者的表示以外,还加入了另一个任务来更好地匹配线上的推荐逻辑。具体来说,由于线上的推荐过程包含了检索、排序在内的多阶段步骤,所以仅仅获得语义相关的向量表示是不够的(例如,基于cos-similarity优化的对比学习向量表示只能增强检索阶段的效果,但对排序阶段的效果增强不够显著,甚至会起负作用)。作者引入了easy/hard negative sample的概念,加入了另一个学习任务,使得获得的向量表示对线上使用更加有效。
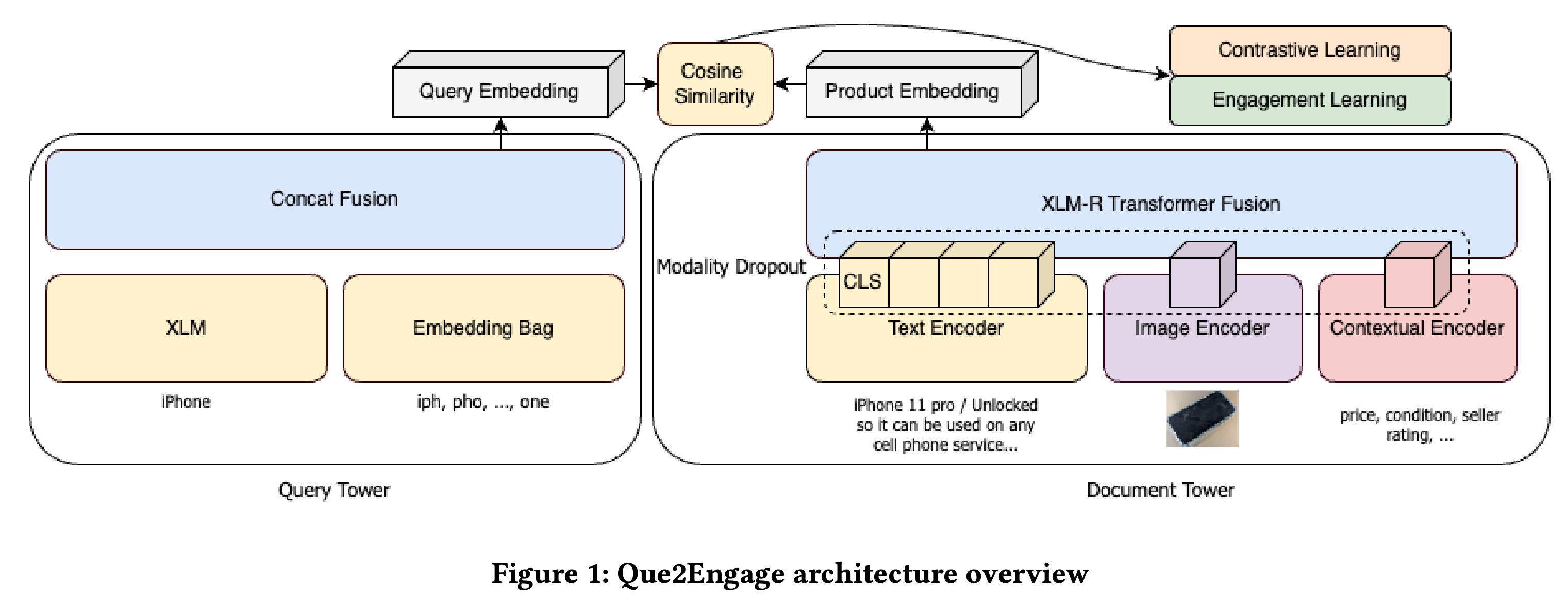
具体来说,输入的样本是 <用户query,推荐商品> 对,样本对中的每一条数据意味着用户在输入query后,对于推荐的商品 进行了互动。这个概念相对重要,因为需要与后面的hard negative sample区分开。
通过构造批次内负样本,可以进行对比学习,从而获得query与商品间的表示向量,以使得相关的向量的相关性最大。对比学习的损失函数为:
简单解释如下:$B$为当前batch size,对于batch中的每一个正样本对$(q_i,d_i)$,可以构造$B-1$个负样本对$(q_i,d_j)$,损失函数旨在最大化真正的正样本占所有样本对的概率:
也代表最大化softmax后的分子,极端情况下,分子的logits值很大,分母的logits趋近于分子的值,softmax后大括号内分式的值 $\frac{\exp \{s\cdot k(q_i,d_i)\}}{\sum_{j=1}^B\exp \{s\cdot k(q_i,d_j)\}}$ 趋近于1,因此损失趋近于0。
其中,$k$表示的是某种度量相关性的指标(例如cos-similarity),$s$表示一个放缩值,在这个实验中作者选择的是20。将logits乘以一个固定值后再做softmax,能够从某种程度使得分布更加的sharp,从而加快收敛的速度。
以上的描述其实是对传统的对比学习样本构造的描述,在论文中,作者提出了一个新的问题:在当前的任务中,这样构造的负样本有些过于容易学习了,例如:我们选择了正样本对 <小棕瓶,雅诗兰黛小棕瓶> ,这是一个用户进行了交互的正样本,假设同批次里另一个样本是 <苹果,山东红富士> ,这样对于前者,我们构造出来的负样本是 <小棕瓶,山东红富士> ,这是一个用脚趾想都不对的负样本推荐结果,作者管这种传统对比学习在同批次内构造出来的负样本叫“简单负样本”(easy negative sample)。 —— 由此我们能够明白,为什么作者认为这样的传统学习只能增加样本间的相关性,提升系统中召回阶段的效果,但对于实际系统的排序过程反而会起到负作用 —— 山东红富士 压根不会出现在搜索小棕瓶后的推荐名单里,所以模型的训练目标完全没有顾及到系统的排序阶段。
为了解决这个问题,这篇论文的亮点在于提出了另一个辅助任务,从而将传统的对比学习任务变成了一个多任务训练的设定。辅助任务的损失函数如下:
其中$c_i=s\cdot k(q_i,d_i)$。
这不就是一个简单的BCE嘛!那它究竟有什么不一样呢?值得注意的是,这里的样本对其实是由真正的正样本,与作者构造的“困难负样本”构成,而这个辅助任务也就是希望模型能够区分正负样本的一个辅助分类任务。困难负样本,是作者特意从实际的系统中搜索得到的,当前系统在用户query后给出了推荐,但没有被用户触发交互的商品。
通过这个辅助任务,就能在通过对比学习增加样本对的相关性的同时,也顾及到模型进行排序的能力,因为模型需要真正认识到究竟哪些样本是用户真正会点击的,而哪些样本相关性虽然高,但不会被点击到的。
最终多任务学习目标的损失函数如下,其中$\lambda$是控制任务重要性占比的超参数。
在学习过程中, 困难负样本与正样本一起在对比学习中被视为正样本 ,而只在辅助的分类任务中被打上不同的标签以作为区分,这样就能在不改变对比学习的学习模式下,引入一个新的任务了(只需要给每个样本对一个辅助标签,表示是否被用户触发后续的交互)。
在实验中,作者实际收集了150m个 展示给客户的样本对,其中有75m个是实际获得用户交互的,剩下的作为困难正样本使用。整体的训练效果如下图所示:
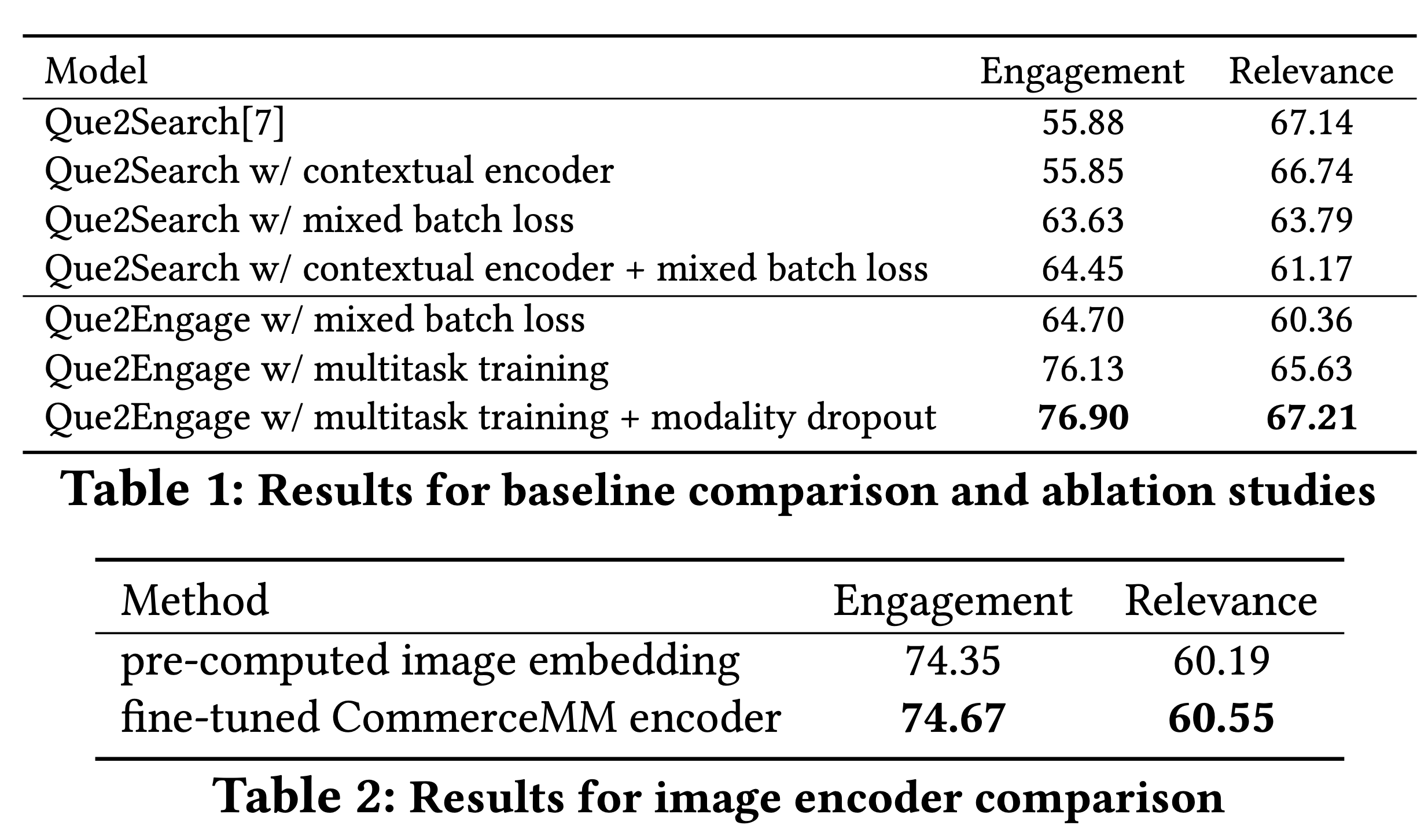
表1是Que2Engage的表现(我理解和之前同组提出的Que2Search只是替换了一半的样本 - 如果样本数量是一致的话 - 并加了一个辅助任务),可以看到加入了多任务训练以及modality dropout以后,新模型能在相关性保持基本一致的情况下,很大幅度地提升了交互方面的性能。
modality dropout是作者在文中提出的一个随机mask一些embedding的方法,但从实验结果来看其实只是想用一些trick保证relevance metric不比原来的更低,所以在这里就不赘述了。