浅谈无监督场景下的句向量表示方法
如何无监督地获得一个句子的向量表示?
或许上过NLP或大数据课程的同学会想到课程小作业的王者:TF-IDF。掌握一些NLP基础的同学可能还会想到静态或动态的词向量:Word2Vec、GloVe、ELMo,BERT——有着探索精神的同学或许会再试试BERT的一些为人所熟知的变种:RoBERTa、DistillBERT。对BERT的结构及其各层表达能力有所了解的同学(底层学基础特征,中部学句法信息,上层学语义信息)1会试着取出多层的词向量表示后再做聚合。当然,还需要将这些词向量汇总成一个句子的最终向量,不外乎求和、平均、各种Pooling……最后,也会有同学去寻找一些专门为词向量表达能力进行过强化的预训练模型Sent2Vec、SentenceBERT。总之,换模型、换方法、换idea,已经21世纪了,调参调包谁不会呢?
有所不同的是,除了盘点上述常用的无监督句向量获得方式外(作为快速获得无监督词向量的途径,上面的方法在落地时具有轮子齐全、即插即用的巨大优势),本文还将介绍一些获得无监督句向量表示的较新方法。这些方法或是解决了上述方法在形式上过于简单粗暴而存在的一些问题,或是在句向量表达能力的评估系统(如STS tasks)中具有压倒性的优势——众所周知,在21世纪,SoTA与Accept呈显著正相关。
现在就让我们开始吧。
本文第一部分会介绍基于词袋模型的一系列句向量表示方法,第二部分主要讲述基于预训练词向量的Power Mean Embedding表示方法,第三部分将通过4篇论文串讲的方式,从0到1地介绍对比学习(Contrastive Learning)在无监督句向量中的应用,最后在文末整理了一些值得思考与讨论的点,希望能为大家的工作带来一些微小的启发。
Real-unsupervised methods
首先进场的是无监督场景中的无监督代表队。
顾名思义,这一类方法完全不需要额外的训练或预训练,它们大部分由Bag-of-Words的思想衍生而来,通过(1)从句子中提取表达能力相对较强的词汇,并(2)采用某种编码规则将其转换为数字形式,最终获得句子的向量。
值得注意的是,这类依赖于词表的(包括下面的Word2Vec等——但经过了预训练的Word2Vec模型不在此范围内,因为它已经给定了词表)方法会受到上游的一些诸如tokenization、lemmatization与stemming在内的数据预处理结果的影响。所以想要更好的使用这类方法,需要注意数据预处理的方式。
Bag-of-Words思想
假定我们已经拥有了一个分词后的句子库$S$,通过扫描,就能获得全量句子的一个总汇性词表$V$(假设该词表是有序的)。那么,我们就能将每条句子变成一个数值向量,这个向量的长度就是词表的大小$|V|$,向量在位置0处的值就是词表中第1个单词在该句子中出现的次数、位置1处的值就是词表中第2个单词在该句子中出现的次数,……,以此类推。
显而易见的是,这个方法是存在问题的:在词表大小很大的时候,储存句子的向量会变成一件十分耗费资源的事情。从直觉上来说,我们应该使用的是一些能更好的有信息表达能力的单词,而删除一些总出现频次过少(生僻字)或总出现频率过高(常见字)的单词,而TF-IDF就较好地具备了这些能力。
TF-IDF
解读TF-IDF方法细节的博客十分常见,在此不再进行赘述。简单来说,该方法通过TF项:单词在当前句子中的出现频次/频率,来表示当前词汇在句子中的重要程度;通过IDF项:单词在所有句子中出现的频率(的倒数的对数),来表示当前词汇是不是过于常见。正好匹配原生BoW思想中所存在的缺陷。此外,类如scikit-learn等机器学习库中的TF-IDF方法还有一些如n-gram或者max-df等额外参数,来帮助调参侠们更好地控制产出特征的质量。
Simhash
与TF-IDF不同,Simhash走了另一条解决问题的道路——有损信息压缩——来节省耗费的资源。Simhash是一种局部敏感的hash算法,最初被Google用于亿万级别的网页去重。所谓局部敏感,也就是当句子做出一些细微的改变的时候,基于Simhash获得的句子向量也只会产生微小的变化,而非像传统hash那样整个签名完全发生改变。
具体而言,对于一个句子,首先使用TF-IDF等BoW方法获得句子内权重最大的$N$个单词,随后通过一种或若干种hash算法将每个单词都变换为64位的01二进制序列。遍历该序列,将值为0的位置手工修改为-1。这样,每个单词都被变换为了只包含$\{-1, +1\}$的序列。在求整个句子的hash值的时候,只需要把它前$N$个单词的序列对应位置相加。值得注意的是,相加操作后,我们需要将现在$<0$的位置再次修改为0,从而使得句向量重新变回一个二进制序列。
要判断句子间(段落/文本)的相似度差异,只需要对这两个句子的Simhash值进行异或,并判断异或后64位中1的个数即可。1的个数越多,则代表这两个句子间不相似的位数越多,即越不相似。
SAUCE
SAUCE2是今年的CIKM中一篇比较有趣的工作,同时也使用了BoW的思想来提取文本表示向量。SAUCE的立意其实与Simhash更为相似一些,即为了快速检索相似的文本 —— 再具体一点讲,SAUCE提出的大背景是:我们已经具有了相当丰富的预训练模型,而我们往往希望将这些模型应用到我们domain-specific的任务中。与这个目的相悖的是,BERT等预训练模型为了具有更加general的文本表示能力,都是在Wiki等通用语料上进行预训练的。因此产生了一个新的需求:我们希望能够给定一些领域相关的语料作为种子(corpus seed),来对大规模网页文本进行检索,获得大量相似的领域内文本,从而对通用的预训练模型进行进一步的训练(post-pretrain),提升它们在具体领域内的表示能力。
假定总文档数为$N$,首先,像所有的BoW方法一样,SAUCE产生了一份所有文档具有的单词词表$V$。上文已经提到,直接进行文档的向量化会导致每个文档的向量大小都是$|V|$。为了进一步缩小维度,SAUCE计算了每个单词出现的文档数$DC$(Document Count),即:
其中$\mathbb{I}$是指示函数,当$\tilde{w_m}$出现在第$i$个文档$D_i$中时为1,否则为0。
SAUCE基于$DC$来实现维度的缩减,提出了两个用于控制维度的阈值:
$k_1$用于筛除出现频次过低的单词,即简单粗暴地删除所有出现频次不到$k_1$的单词。删除后的维度被快速缩减到:
$k_2$用于控制保留的数量,即在经过$k_1$筛选后,接下来只保留剩余单词中$DC$最小的$k_2$个。这个控制方式更加粗暴,强行把向量维度控制到:
然后呢?然后没有了。因为精美的食材,往往只需要简单的烹饪。
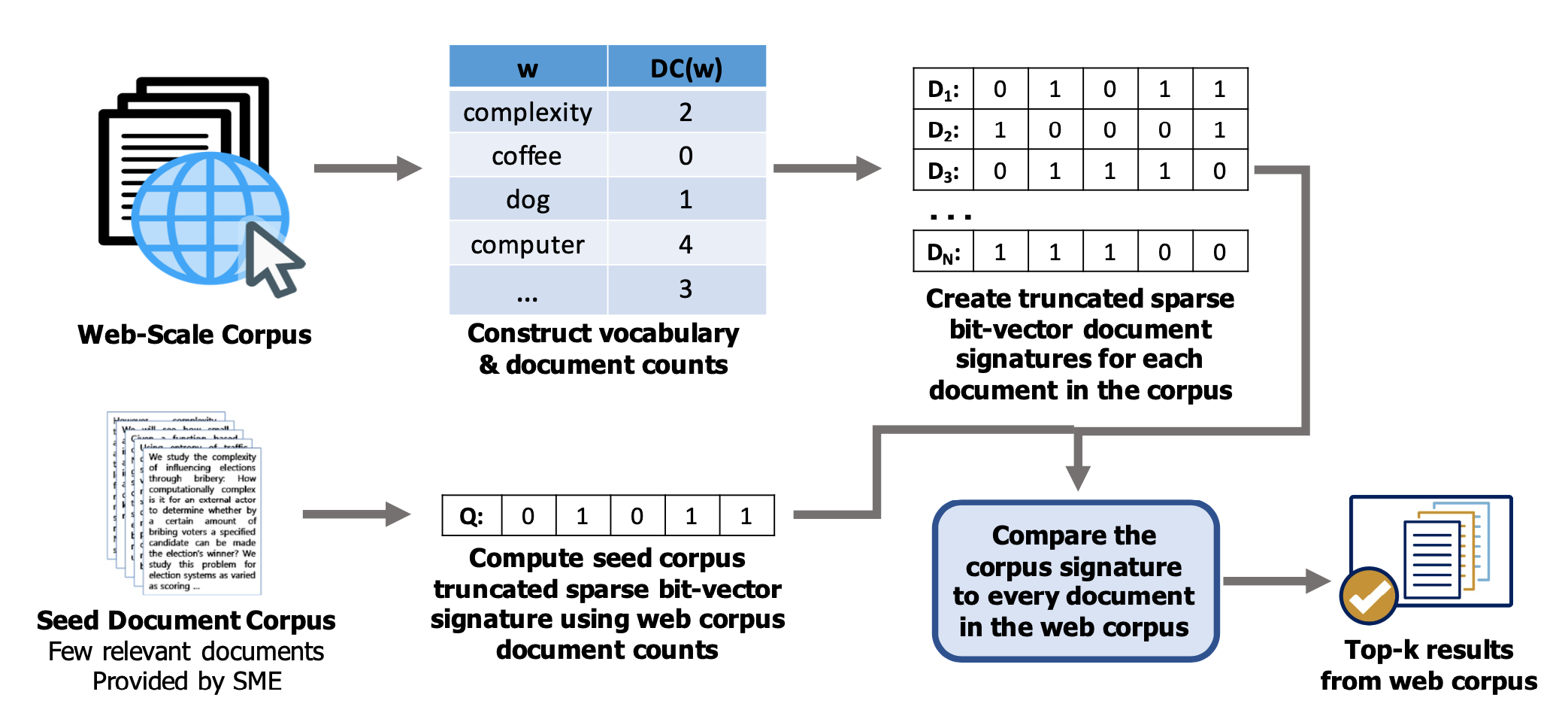
下图是作者提供的算法伪代码,让我们再过一遍:

(1)算词表;(2)算$DC$;(3)卡阈值$k_1$;(4)卡阈值$k_2$。伪代码里用了一个for循环来实际执行每个文档计算向量的方式,引入了$R\subset J$,看起来比较繁复,实际上就是对筛选出来的$k_2$个单词,依次判断是不是在当前的文档中。最后对每个文档都算出一个$k_2$维度的01二进制向量。
尽管听起来是一种非常粗暴的控制方式,但实际上SAUCE仍然为BoW提供了一个完整的解决方案:$k_1$用于删除整体频次过低的单词,效果与TF-IDF中由于进行频次控制的TF部分相似(并不完全相同,可以理解为将TF中的频次控制从文档层面上升到了整个语料层面);$k_2$用于保留剩下的单词中出现频次最低的数量,意味着出现频次过高的单词被删除,效果与TF-IDF中删除常见词的IDF部分相似。
作者在 Astronomy 和 Bottle water 两个领域的数据上,和 Random, TF-IDF, Hash, RoBERTa 等方法进行了比较,SAUCE在计算时间与查询覆盖率上均显著由于这些基线方法。由于文章主旨是corpus expansion,在实验时也沿用了这一类的setting,与本文相关性不大,因此不再叙述。此外,SAUCE也提出了完善的系统级更新语料的流程伪代码,以及对应的部署细节,本文仅展示论文中的流程图,感兴趣的同学可以去看完整的论文。
总体而言,SAUCE为我们提供了另一种文本表示的思路,同时也让我们确信:想要使用好BoW类的方法,就要解决上面提到的两个缺陷。SAUCE使用两个超参数$k_1$与$k_2$来实现了这一点,然而,相较于自适应所有大小语料的TF-IDF,SAUCE给定了两个依赖于总文档数、总词汇数的超参,其实会给想要使用该方法的同学带来一些困惑:我该怎么设置这两个参数?大还是小,依据是什么?另外这种受限于语料统计特征的方法也无法进行快速的迁移。天下没有免费的午餐,也希望同学们都对手上的任务与数据有充分的了解后,再来选择适用的方法。
Bottom-up methods & Power mean pooling
由于BoW类方法的特性,上文中所提到的一些方法其实并不囿于句向量的计算 —— 或者说提出的初衷主要是用于对段落、文本的表示,这是因为较长的文本信息中更容易提取出有效的单词或词组。正因此,TF-IDF、Simhash与SAUCE等方法都或多或少地强调了方法应用于大规模快速检索的能力。而接下来的篇幅中,我们将真正回到主题,开始叙述词向量的学习与表示。让我们从一个奇妙的方法:power mean pooling3(下称PMP)开始说起。
之所以说PMP奇妙,是因为它一定程度上实现了调参侠们的心愿:网格搜索找参数?逐步回归选特征?我全都要!
文章最开始提到,由于预训练语料、任务的选择不同,市面上提供的预训练的特征丰富多样。而关于这些特征的选择,不同的人具有不同的偏好:李某喜欢GloVe的任务中精巧设计的共现逻辑,王某认为简单好用的Word2Vec是不朽的经典,而张某是预训练模型的忠实拥趸,为大力出奇迹的BERT词向量所倾倒,当然,想必也有同学尝试过将这些预训练向量拼起来。PMP就向大家展示了:直接把现有的预训练特征及其组合拼起来,也会在下游任务上有很好的效果。
具体地,首先文中引用了power mean的形式化定义:
其中,$x_i$表示一个长度为$n$的句子中,第$i$个单词的词向量。$p$是一个超参,能取到任意实数或正负无穷。
显然,在 $p=1$ 时,上式就代表了最常用的取平均方法:将句子中所有token的向量求平均,作为句子的向量。而在 $p\rightarrow +\infty$ 时,该方法等同于保留每个维度列中最大的值; $p\rightarrow -\infty$ 意味着保留每个维度中最小的值。虽然大家常用的是平均法,但是这些聚合方法都是有损的压缩,其实很难说出孰优孰劣,因此作者认为:它们都从某种角度保留了自己觉得重要的信息,但同时又损失了一些信息,那么直接将它们拼接起来,是不是能够保留更多有效的信息呢?
直觉上而言,取不同的$p$都有其独特的意义(值得注意的是,文中也提到,当$p$取偶数的时候,词向量的embedding会被消除负号,天然产生信息损失,因此并不是一个特别理想的选择),作者选取了大家所常用的 $1,\pm\infty$ 三个$p$值。对于词向量,作者选择了以下四种:
- (GV) GloVe embedding: trained on Common Crawl
- (GN) Word2Vec: trained on GoogleNews
- (AR) Attract-Repel
- (MS) MorphSpecialized
每类词向量都是300维,因此如果将所有出现的情况排列组合,最长的情况下维度会达到:$4\times 3\times 300=3,600$ —— 和你目前可能在想的一样,作者提到:用这么大的维度去比一些使用词向量聚合、维度可能连1000都不到的方法是不太公平的,因此作者主要比较了 InferSent 方法,后者的词向量达到了4,096维。当然为了基线方法的丰富性,作者也另外加入了对 SIF(dim=300)、Siamese-CBOW(dim=300) 和 Sent2Vec(dim=700) 方法的比较。
作者在AM/AC/CLS加上SentEval共计9个任务上评估了PMP的效果(具体的任务设定可以参看原文的表1)。在使用PMP句向量时,作者加训了一个逻辑回归分类器,结果如下表所示:
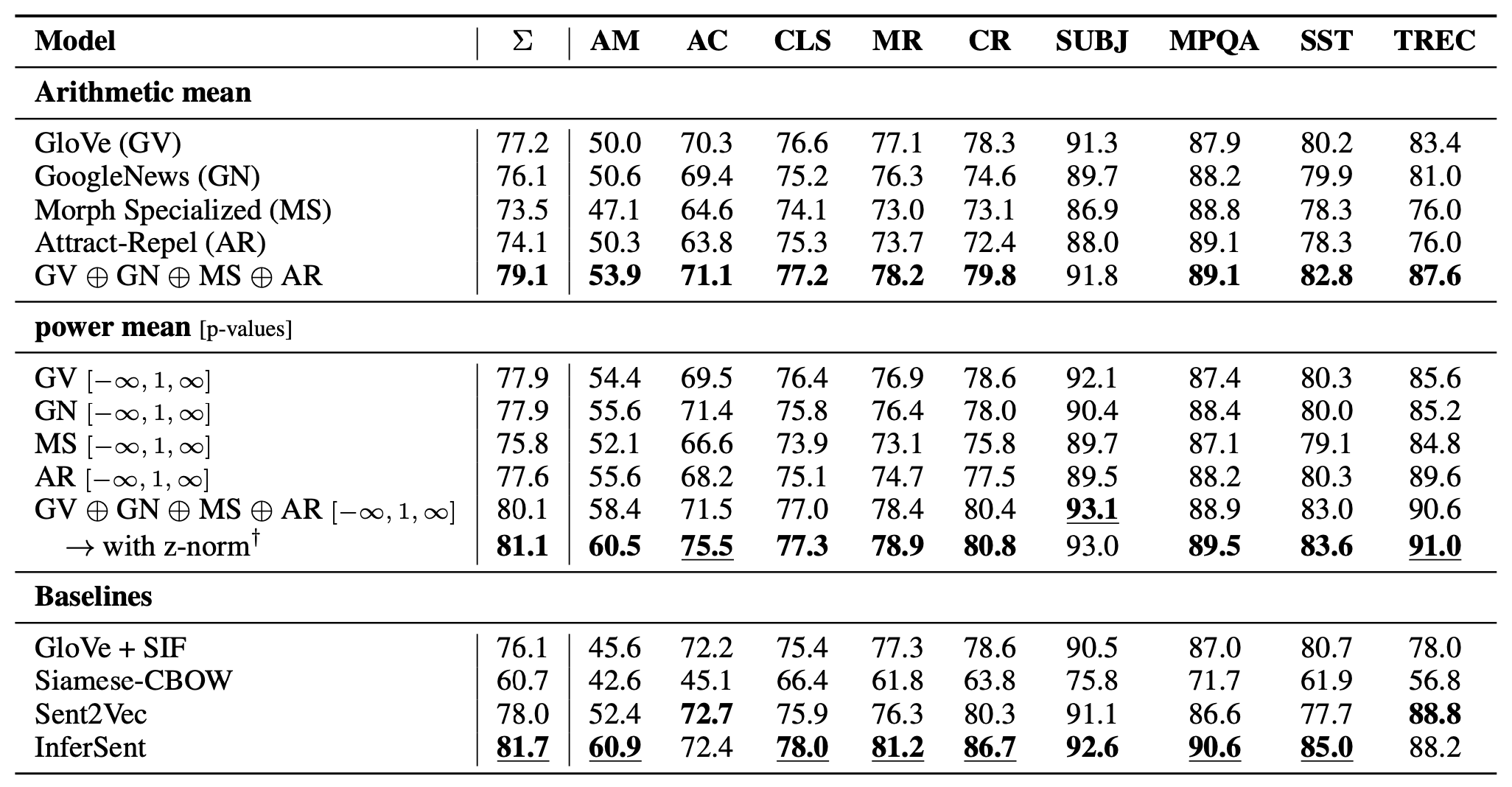
表的上部第一个栏目比较了单独使用词向量与全部词向量取平均之间的效果,可以看到把四个向量拼接以后,使用平均求得的句向量(Arithmetic mean意为算术平均,即 $p=1$ )效果显著优于独立使用四种词向量。但是话说回来,这一栏实际是在拿维度1,200去比较维度300的向量,显得有些不公平。
说到这,不知道有没有小伙伴比较好奇:如果使用BERT+LR的形式去做这些任务,效果会不会更好?因为BERT只用了768维度的词向量,资源占用是比1,200维度低不少的。而如果是的话,是不是说明相较于拼接不同的词向量,选择一个表达能力更强、嵌入语义更丰富的词向量,对于下游任务会有更明显的帮助呢?
先来回答第一个问题:由于BERT原文在GLUE和SQuAD等数据集上进行了测试,没办法进行直观的比较,但是 Sentence-BERT(SBERT) 4 在实验时使用了相同的SentEval评估数据,所以我们可以通过SBERT的实验结果来进行间接的比较:
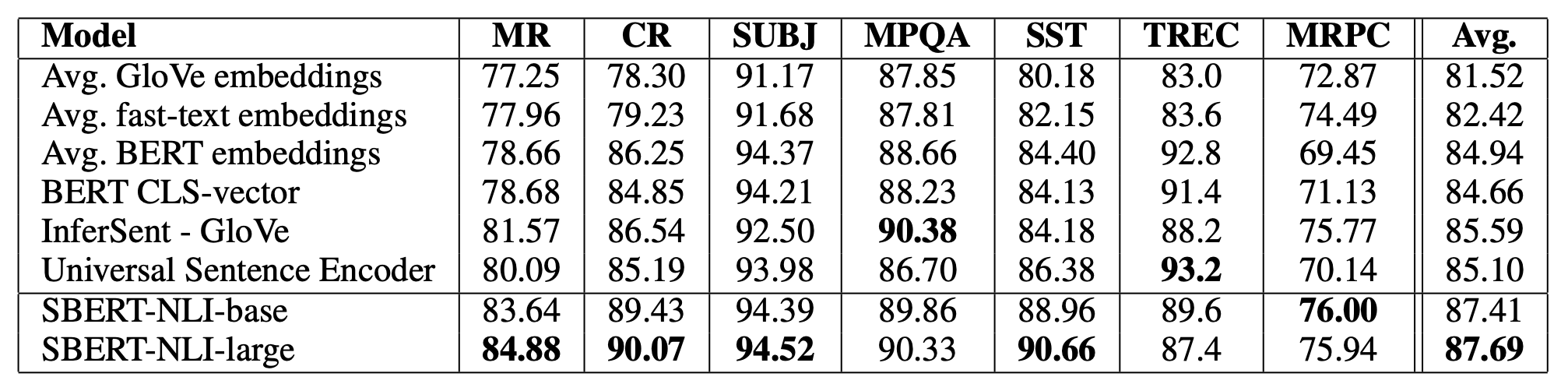
在SBERT的实验结果中,第一行对标了PMP结果第一行的GloVe,两者的结果几乎是一致的,说明实验结果确实横向可比,而我们略过表中所展示的SBERT实验结果(对不起作者,把你当工具人了),直接看文中第四行所展示的 使用BERT CLS向量作为句向量 时的评测结果。可以发现,使用768维的BERT CLS已经在绝大部分的任务中超过了3,600维度的PMP,甚至在一些组中超过了InferSent。所以第一个问题的答案是显而易见的:选择一个表达能力更强的词向量,会比拼接现有词向量以及使用PMP效果更佳。结合作者在论文中的结论:拼接词向量对于整体句向量表达能力的提升优于使用PMP,我们可以对上面的第二个问题得到一个总括性的结论:
- 在内存等资源限制的情况下,对于有限的词向量维度,选择泛化能力更强的词向量更佳;
- 在词向量表示能力相近的情况下,对于有限的词向量维度,优先使用已有词向量拼接取平均($p=1$),效果会优于使用不同的$p$值得到的同一词向量的扩展结果;
- 在资源允许的情况下,在以上条件里再加上PMP,进一步扩展词向量维度,能进一步提升最后生成的句向量的表示能力。
- 此外,作者还专门提到:在PMP基础上加上z-norm,能进一步提升PMP的应用效果。
在漫长的讨论之后,我们回到正题:PMP效果表中的第二栏主要展示了使用不同的$p$值对于结果的影响,可以发现,拼接不同$p$值的向量也会提升在评测数据上的效果。最后,使用全量数据集、全量$p$值的3,600维句向量,效果已经和InferSent不相上下。 当然,在所有的结果中,只有全量拼接(3,600)与InferSent的比较是相对公平的。 作者主动提出了不同维度间的向量比较有失公平,却在实验中没有进一步维护自己的观点,这点有些令人遗憾。
当然,总的来看,这篇文章仍然为同学们提供了一个行之有效的方向,让大家不再觉得自己把现有的词向量拼接起来使用是一种玄学的事情,而是将其作为一个提升句向量表示能力的一个可选工具。
The road to constrastive learning
接下来是笔者觉得当前非常有意思的一个方向:对比学习(contrastive learning)在无监督句向量生成中的使用。在本节中,你会看到众多才华横溢的研究者们是如何从词向量学习扩展到句向量学习、如何从单一的学习目标扩展到对比学习的目标、如何从传统hard label的分类任务到contrastive label的对比学习任务,以及探索如何更好的选择对比学习的正负例。笔者精选了从15年开始的5篇文章,希望能通过对它们的解读达到窥一斑而知全豹的效果,让大家对这个方向有一个总括性的了解。
Skip-Tought Vectors
还记得Word2Vec里学习词向量的经典方法:skip-gram吗?它的学习目标是:给定一个单词,判别式地预测它前后出现过的单词。这个学习目标本质上是希望(1)学到该单词的上下文信息,并且(2)使得拥有相似上下文的单词拥有相似的表示。从这一点来看,skip-gram和GloVe通过共现矩阵(co-ocurrence matrix)进行学习,从而让共现情况相似的单词具有相似的表示有异曲同工的设计。
上文已经提到,如果使用Word2Vec具有的词向量取平均作为句向量,这一类bottom-up methods会损失信息。PMP方法使用不同的$p$值缓解了信息,却没有从学习目标的角度解决这一问题 —— Skip-Tought 5 方法就为这一问题提供了一个解决思路:如果把skip-gram从句子角度放大到篇章角度,这样学到的不就是句向量了吗?唯一的区别在于,前者的训练单元(unit)是word,后者的训练单元是sentence。
当然,正如skip-gram隐式要求句子内单词是有序的一样,skip-tought要求输入的句子间是具有上下关系的,这一点或许会在应用skip-tought时成为制约。特别地,作者的实验中要求输入的语料需要是连贯的$$三元组。
在实现的时候,还有一个直接的问题:句子的多样性比单词要大得多,训练词向量的时候有词表,但训练句向量不能用句表,否则embedding table可能大到整个恒河都装不了。作者使用了当时炽手可热的Encoder-Decoder结构来解决这个问题:使用GRU单元的RNN来作为encoder,来获取当前句子的表示向量,再使用decoder来产生该句子的上下文。在文中,上下文特指上句与下句(好比skip-gram只预测当前单词的上下各一个单词)。特别地,因为句子的嵌入信息会比单一的单词要更多,所以作者使用了两个decoder来分别生成当前句子的上句与下句。下图是输入语料的示意图:

输入中间句“I could see the cat on the steps \”后,分别用两个decoder生成了上句“I got back home \”以及下句“This was strange \”。训练目标定义上下句生成结果的概率和,即给定encoder的输出$h_i$,前面的时间步里已经生成的所有单词$w^{<t}$,最终生成当前单词的条件概率$w^t$之和:
在效果评估阶段,作者在sematic relatedness(SICK), paraphrase detection(MS Paraphrase Corpous), image-sentence ranking(COCO)三个任务上验证了skip-tought vector的有效性,其中也尝试了不同类型的encoder(unidirectional/bidirectional)。值得注意的是,作者设定的encoder输出向量维度是2,400,在用于评估的sentence-pair任务中,对于句子$u$,$v$,作者使用了$concat(u\cdot v, |u-v|)$的形式构造得到用于分类的向量,也就是说分类向量达到了4,800维。最终的结果与SoTA都是可比的 —— 除了Dependency Tree-LSTM,作者说这是因为后者在数据处理时引入了parser带来的外部信息。
SDAE
和skip-tought使用Encoder-Decoder解决问题的思路不太一样的是,SDAE 6(顾名思义)选择了用DAE来无监督地获取句子的向量。上文中提到,skip-tought有一个比较明显的缺点是:输入的语料必须是连贯的三元组,而DAE(denoising auto-encoder)的特点是可以对加入噪声前后的句子本身进行学习,从而避免同时输入句子的上下句信息。
特别地,对于一个输入的句子$s_i$,作者通过两个超参数$p_o, p_x$控制句子的两种增强:
- 对于句子$s_i$中的每个单词$w_i$,以$p_o$的概率对它进行删除;
- 对于句子$s_i$中的连续两个单词$w_iw_{i+1}$,以$p_x$的概率对它们进行交换。
以增强(加入噪声)后的句子作为输入,要求模型输出原始的句子,这就是SDAE(sequential denoising auto-encoder)的基础思想。与skip-tought一样,作者使用了基于LSTM结构的encoder-decoder进行训练,在使用句向量时,对于有监督任务,作者在句向量上加入LR来进行模型的tuning;对于无监督任务,直接计算句向量的cos相似度,并与标准结果进行比较。以下是在无监督评估数据上的实验结果:
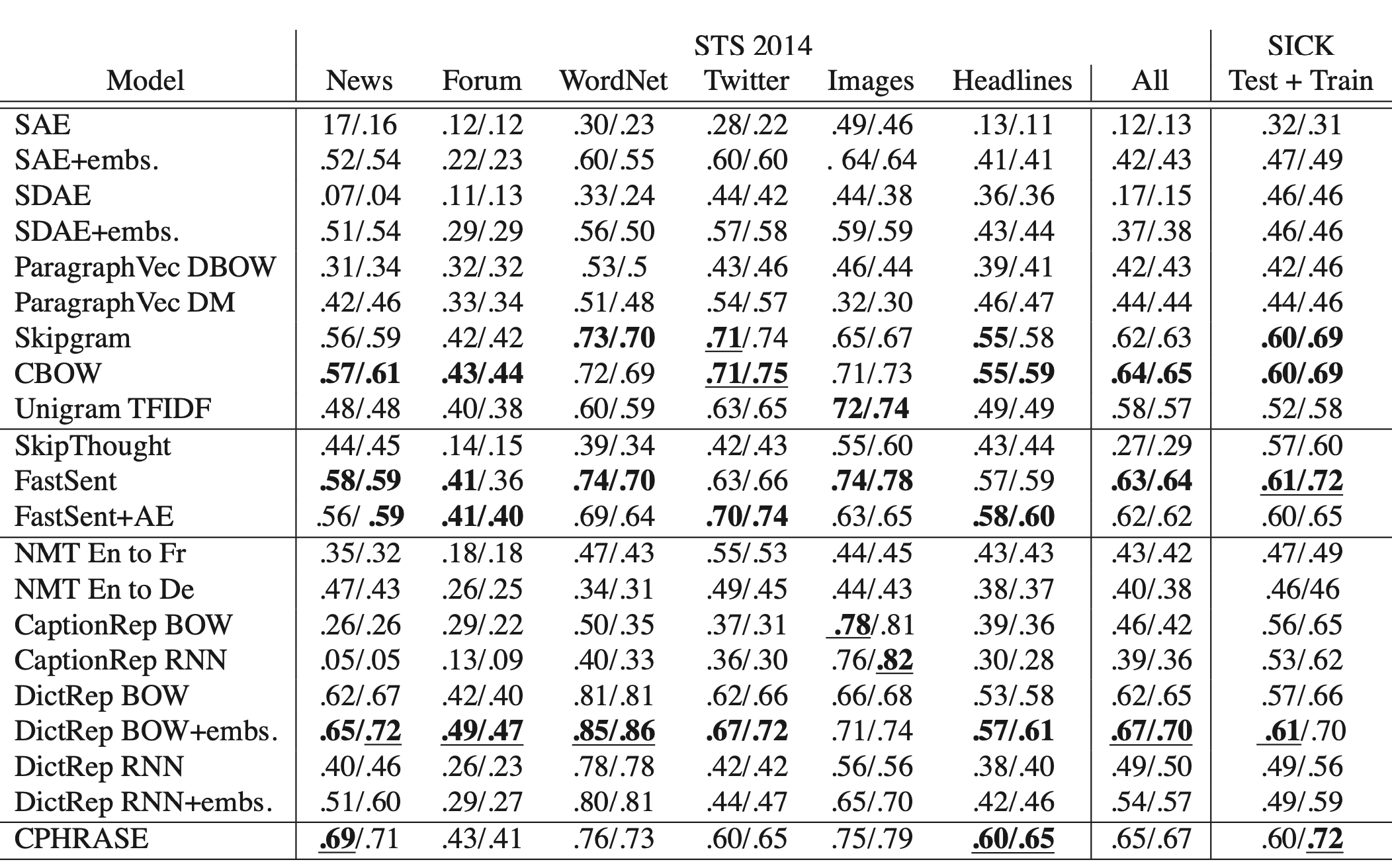
在第一栏中,比较SAE与SDAE的结果可以发现,后者在Twitter等比较noisy的数据上有明显提升,这佐证了引入两种概率增强方法的有效性;然而在完全无监督的情况下,整体效果最好的仍然是两类Word2Vec的实现方法,并且即便是基于unigram的TF-IDF也在大部分的验证任务上好于其它模型。对于论文本身而言,这并不是一个特别fancy的实验结果,作者在文中也没有明确给出这个现象的解释(我们将在本文最后的思考部分正式抛出这个问题)。
中场休息
skip-tought与SDAE都使用了encoder-decoder结构,但采用了两种截然不同的思路:前者使用了两个decoder分别预测当前句子的上下句,因此需要输入连贯的句子;后者采取DAE的思路,输入加入噪声后的句子,让decoder尝试复原出原始的句子。这两个方法虽然看起来有些差别,但有一个特性是相似的:decoder学习过程中的学习目标都是hard label。
什么是hard label呢?有对模型蒸馏或者噪声学习等方向有所了解的同学可能知道,hard label就是把模型要预测的目标设置成1,即我们明确认为这个学习目标是绝对正确的:在对模型进行蒸馏时,我们一般认为gold label中会带有少量噪声(或者没有噪声,但某些样本的pattern很难学习,从而对模型收敛有所影响),所以除了给定的gold标签以外,我们同时要学习大模型预测的分布,一般是softmax前面层的输出结果,被称为soft label。带噪学习中,由于更加笃定标签是具有噪声的,所以更加倾向于部分使用hard label而非全部采纳,如co-teaching等方法使用了不同模型间的相互学习。
回到正题,那么现在的问题是:我在encoder-decoder结构中,将上下句或是当前句设为学习目标,真的是正确的吗?
这个问题谁也无法回答,但我们从最简单的逻辑关系角度至少可以确定:以上两种方法肯定不可能全是对的,因为他们的学习目标本身就是不一样的。亦或是,他们可能是“对”的,但从NLU整体的发展方向上来说,不会都是“合适”的。
那么什么学习目标是合适的呢?至少可以说,相较于上面提到的两类使用hard label的方法,对比学习(contrastive learning)能帮我们设定一个更加合适的目标,从而帮助我们往正确的道路上多走几步。因为对比学习的目标不是设定一个hard label让模型去学习,而是让我们给定一个考察相似性的方法,随后让模型拉近相似类间的向量距离(alignment),同时尽量使不同的同类别在整个向量空间中均匀分布(uniformity)。作为例子,希望下面提到的QuickTought与SimCSE对大家有所启发。
QuickToughts
结合上面的讨论,笔者尝试用最简单的语言来解释QuickToughts7的改进:将skip-tought的学习目标 —— 上下句的hard label —— 修改为对比学习的学习目标。即拉近当前句与上下句之间的向量距离:
其中:
缺少了一些前置内容,可能公式不容易看懂,但是整体上能够感觉出来,这个式子的目标是:在一系列候选句子$S_{cand}$中挑选出和当前句子$s$最为相似的句子$s_{cand}$。很容易发现,式子2本质上就是一个softmax过程,$c$意为一个计算相似度的函数,例如点积或余弦相似度,$f$与$g$代表这两个不同的模型,可以简单理解为skip-tought中的encoder与decoder。式2的含义就是让最相似的句子对具有更大的权重,并且同时降低不相似句子对之间的权重。这就是对比学习的典型思路了。
下图也解释了这两类方法间的差异:
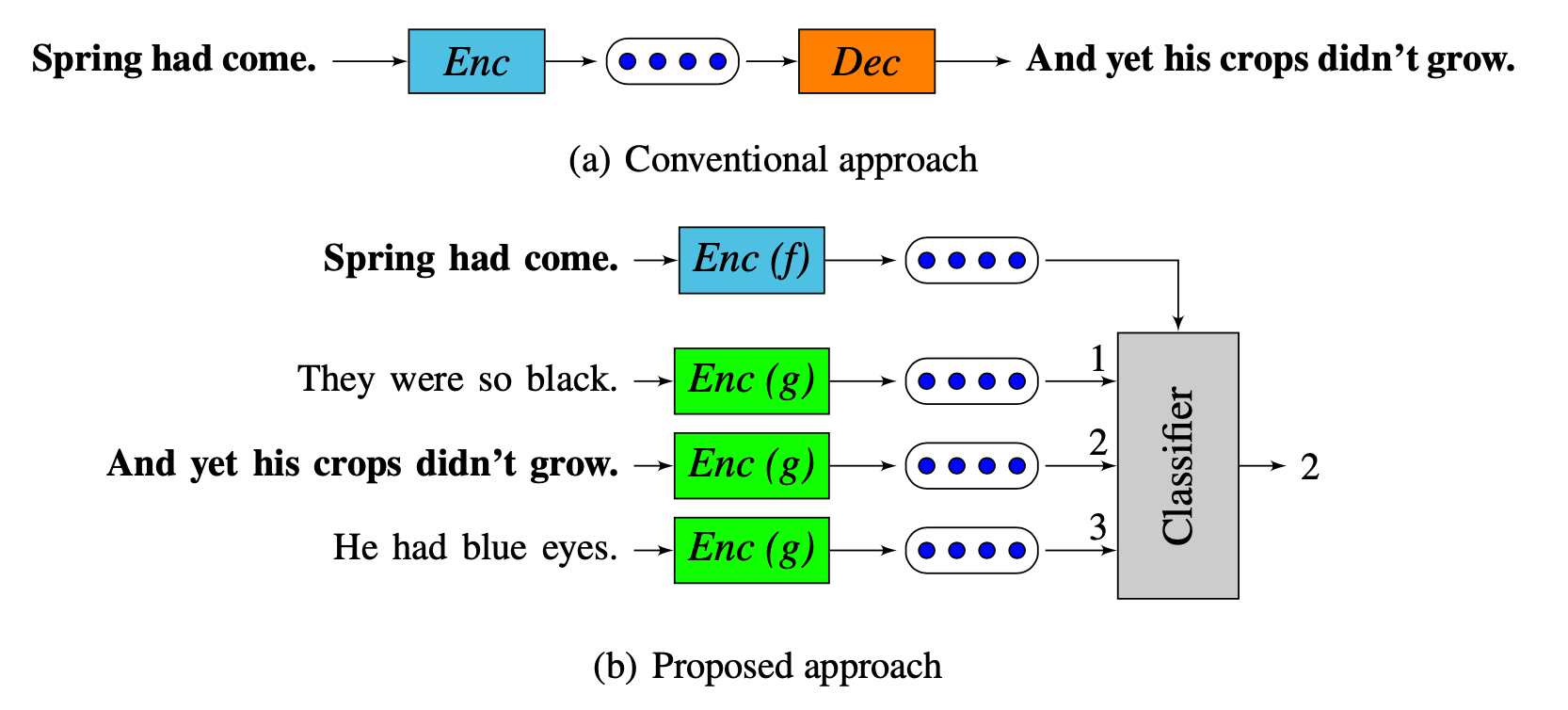
有趣的是,作者还在文中专门提到:在实验过程中也尝试过类似负采样的方式,通过二元分类器来学习hard label,但效果并不如上面的学习目标那么好,并给出了与上文类似的解释:
We found object (2) work better, presumably due to the related constraint it imposes. Instead of requiring context windows to be classified as positive/negative, it only requires groud truth contexts to be more plausible than contrastive contexts.
换言之就是,我们不需要模型具有两两判断是否是NSP的能力,我们只需要模型能从一系列候选句中挑出最相似的那个就好了。
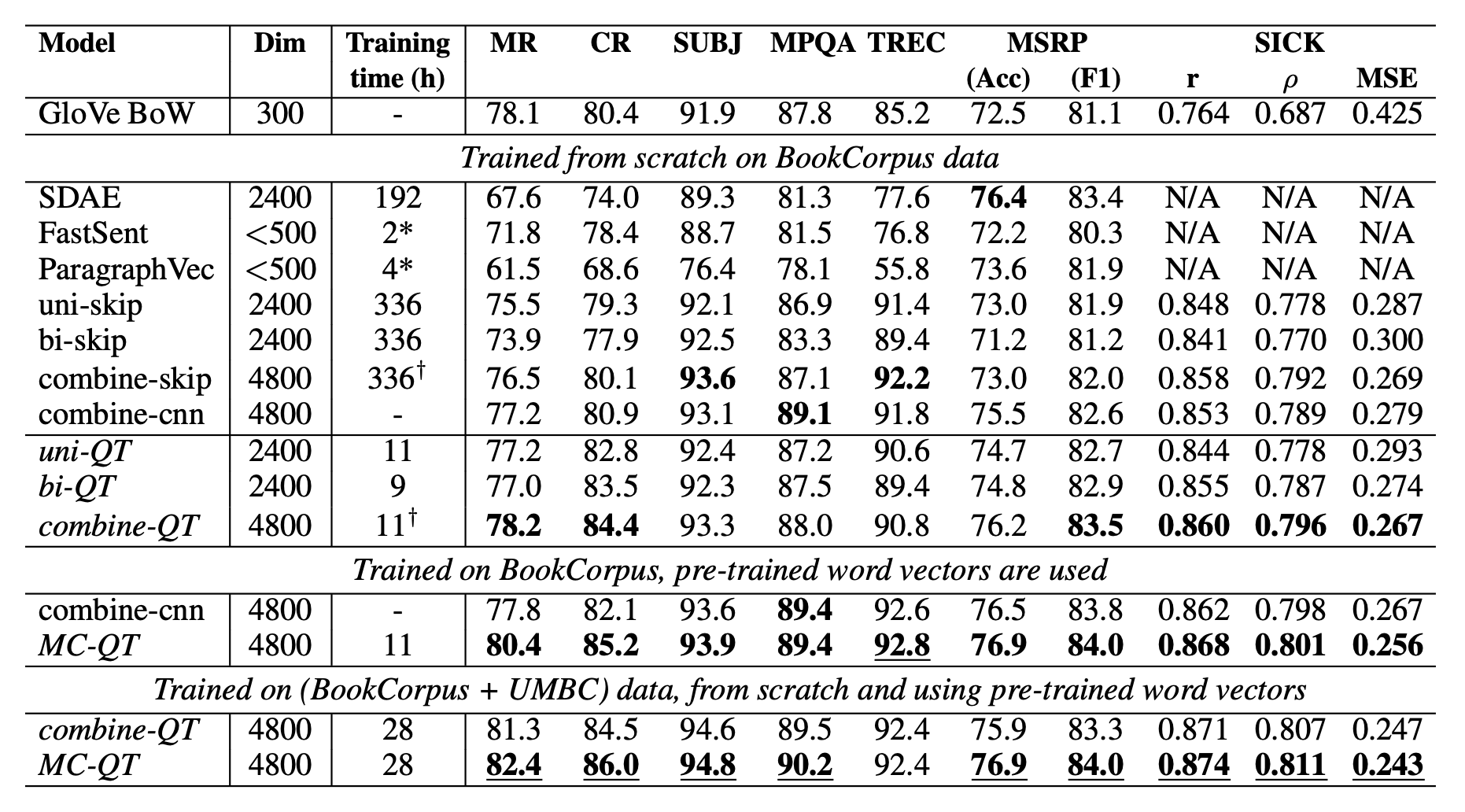
在实验阶段,作者比较了SDAE、skip-tought等传统方法,可以发现:
- 使用BookCorpus语料从头训练时,QuickToughts能在相当一部分任务中和现有方法可比,部分任务上能够超过现有的方法;
- 使用BookCorpus+预训练词向量初始化后,QuickToughts方法在所有任务上都能超过现有方法。
- PMP看到这里可能还是会忍不住怨念一下:诸君这样始终用不同维度的词向量进行相互比较真的大丈夫?
SimCSE
如QuickToughts可以理解为把skip-tought带入了对比学习领域一样,我们可以这样描述:SimCSE8把SDAE带入了对比学习领域。
也正如SimCSE在文章开头就直截了当地展示了该方法超越同侪的效果一样,笔者也在开始就告诉大家SimCSE的方法:使用dropout作为噪声。还记得SDAE吗?它用了两个概率$p_o,p_x$来构造带噪声的句子,然后用生成的方式复原原始句子。SimCSE简单粗暴地使用dropout前后的句向量作为学习目标 —— 当然,由于引入了对比学习,论文的目标变成了:
和QuickToughts的学习目标是不是很像?$h_i^{z_i}$表示使用dropout $z$后的句子$i$的向量表示,$h_i^{z_i’}$表示使用dropout $z’$后的句子$i$的向量表示,由于$z, z’$是不一样的dropout,因此输出的句向量会有所区别,作者就以这个区别作为了DAE中的噪声。
在实验阶段,随着论文的与时俱进,SimCSE已经开始使用BERT预训练模型作为初始化的模型了(上文的$z$也就是transformer里自带的dropout)。实验结果如下表所示:
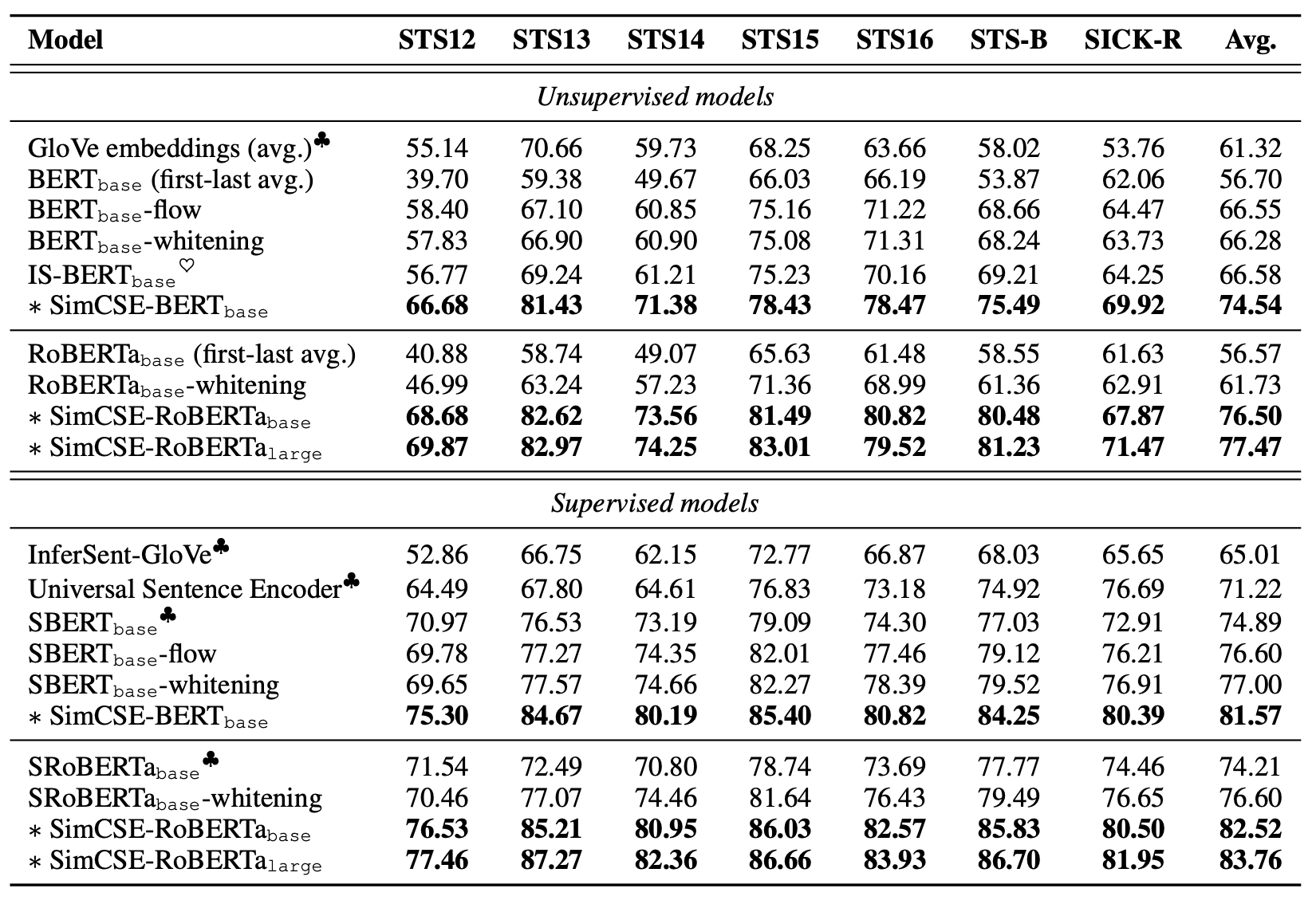
SimCSE在STS的所有任务中都大幅领先于之前的基线方法,部分的提升幅度甚至超过了10\%。在有监督模型的比较中,SimCSE仍能保持相当大的领先,可以说把SoTA向上提了一大步。如此细微的改动能带来如此大幅度的提升,这个结果是十分惊艳的。
除了简单但有效的对比目标以外,论文里还从理论角度解释了其有效的原因,可读性很强,推荐想详细了解对比学习在无监督句向量中的应用的同学可以从这篇文章开始,根据相关工作往前回溯。
讨论与思考
全文行文过程中其实会时不时地提出一些小问题(大部分都带有答案),在这里,笔者主要是想提出一些值得思考的点,它们可能目前尚没有明确的答案,又或者每个人都有自己的想法 —— 兴许思考这些问题,能给你带来一些特别的insights呢?
- 奥卡姆剃刀:尽管篇幅所限,笔者只提到了两篇对比学习的文章,但仍有相当一部分使用对比学习做无监督句向量学习的工作(比如作为SimCSE效果背景板之一的IS-BERT,使用了全局与局部词向量作为对比的目标),但SimCSE用了最简单的方式实现了最出众的效果。有时往往会发现,一些越简单的思路,或许反而会取得越好的效果,如SimCSE之于SDAE(dropout is all you need),MLM之于EDA(mask is all you need),如PMP之于双塔(concatenation is all you need)。兴许在做研究的时候,不要过分注重于模型的转型升级,而是从其它角度试着简化问题,会带来更加有价值的结果。
- Prompt-based Contrastive Learning:或许在很远的未来,我们能获得一个一统天下的模型,它能够胜任所有的NLP任务,但至少从目前来看,我们离这一天还有很长的路要走,在当前,我们想要做一个特定领域的特定任务的时候,还是需要针对性地去设计训练目标。在为人所广泛研究的Language Model(LM)领域,已经有了Prompt-base LM9这个思路,即针对下游想要优化的任务,来针对性地设计预训练目标,定点强化预训练模型在特定领域内的效果。在对比学习中,是否也可以借鉴这个思路(我们可以发现,从SDAE到IS-BERT到SimCSE,就是一个寻找更好的自监督目标的过程),根据下游的任务,来设计一个更好的对比目标呢?
- 顺序的重要性:你是否发现,句向量的获取方法间有一个鲜明的区别:是否用到了上下文。例如:skip-tought要求输入的句子有序,而SDAE不用;QuickTought要求输入句子间的先验关系,而SimCSE不用。更加广泛的,BoW类型的句向量获取方法甚至不要求输入句子里的词汇具有先后顺序。直觉上来说,人类在理解自然语言时,对于词序与句序是有相当强的依赖的,但在NLP里,似乎不用这些顺序信息就能得到很好的效果。是因为NLP的发展不能完全参考人类对于自然语言的理解方式,还是说我们仍未很好地发掘出这些顺序信息所蕴含的潜能呢?
Reference
Jawahar G, Sagot B, Seddah D. What does BERT learn about the structure of language?[C]//ACL 2019-57th Annual Meeting of the Association for Computational Linguistics. 2019. ↩
Wahed M, Gruhl D, Alba A, et al. SAUCE: Truncated Sparse Document Signature Bit-Vectors for Fast Web-Scale Corpus Expansion[J]. arXiv preprint arXiv:2108.11948, 2021. (Accepted to CIKM 2021) ↩
Rücklé A, Eger S, Peyrard M, et al. Concatenated power mean word embeddings as universal cross-lingual sentence representations[J]. arXiv preprint arXiv:1803.01400, 2018. ↩
Reimers N, Gurevych I. Sentence-bert: Sentence embeddings using siamese bert-networks[J]. arXiv preprint arXiv:1908.10084, 2019. (Accepted to IJCAI 2019) ↩
Kiros R, Zhu Y, Salakhutdinov R R, et al. Skip-thought vectors[C]//Advances in neural information processing systems. 2015: 3294-3302. ↩
Hill F, Cho K, Korhonen A. Learning distributed representations of sentences from unlabelled data[J]. arXiv preprint arXiv:1602.03483, 2016. (Accepted NAACL 2016) ↩
Logeswaran L, Lee H. An efficient framework for learning sentence representations[J]. arXiv preprint arXiv:1803.02893, 2018. (Accepted to ICLR 2018) ↩
Gao T, Yao X, Chen D. SimCSE: Simple Contrastive Learning of Sentence Embeddings[J]. arXiv preprint arXiv:2104.08821, 2021. ↩
苏剑林. (Apr. 03, 2021). 《P-tuning:自动构建模版,释放语言模型潜能 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/8295[ ↩](#reffn_9)